Finding similar package names
Have you ever seen two packages with similar names and been unsure of which one to install?
Choosing the right package is a security decision. Malicious software supply chain attacks have increased 633% year over year according to Sonatype’s State of the Software Supply Chain report.
Typosquatting involves an attacker uploading a malicious package with a similar name to a popular package in the hopes that users will be confused and download their malicious package instead. Recent high-profile attacks mentioned in the Sonatype report include rustdecimal typosquatting on rust_decimal, and pymafka typosquatting on pykafka and many packages typosquatting on colors.
The deps.dev team has been thinking of ways to help you find the right package, so we’re excited to launch the similar package names feature on the deps.dev website! These similarity results are available for three open source ecosystems: npm, PyPI and Cargo.
We are currently calculating the following forms of package name similarity:
- Homoglyphs (eg. rns is similar to ms because ‘rn’ looks like ‘m’)
- Permutation around separators (eg. ui-elements is similar to element-ui)
- npm prefix normalization (eg. core-tracing is similar to @azure/core-tracing)
- Levenshtein edit distance of one (eg. tensorflou is similar to tensorflow)
- Or combinations of the above.
Packages may have coincidently similar names due to the large number of packages within the ecosystem, but there are other reasons two packages may have similar names:
- The packages may be intended to be used for different variations of a language (jest is similar to @types/jest)
- The packages may provide functionality of the same category (rson is similar to bson and json)
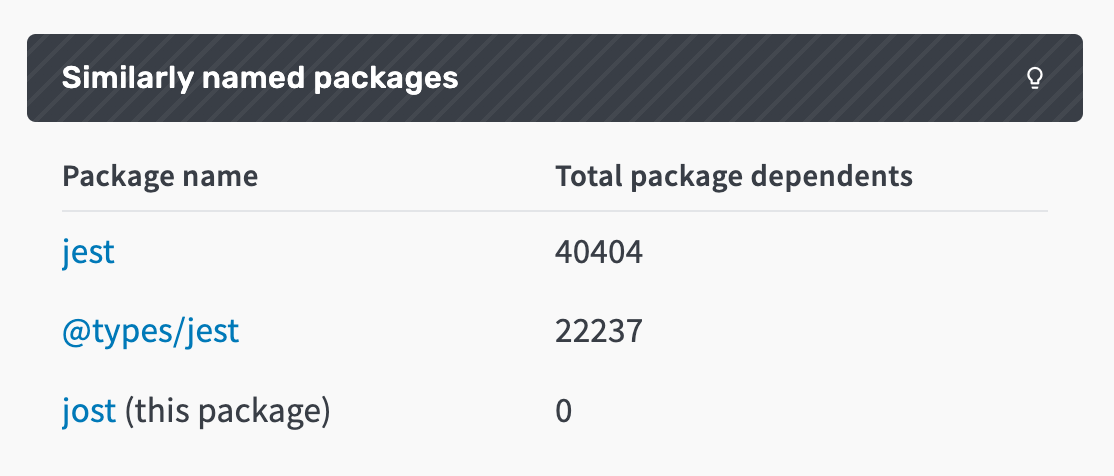
- One package may be named in homage to another more popular package (redrx and redux, jost and jest)
- A package may be intentionally named to confuse users, an attack category known as typosquatting (reacy is similar to react)
We have found that combining similar name calculations with a popularity metric (such as dependents or downloads) helps to narrow down the noise. In particular, prioritizing similar name pairs by dependents helped to reduce uninteresting results. When we calculated similarity for all possible package pairs, we observed a lot of noise; a lot of packages were similar to each other for no reason other than that there are so many packages in each ecosystem, and so few short or memorable names. For this reason, we calculate similarity only to the most popular packages within each ecosystem, which led to more meaningful results. And to make the results even more useful, we’ve ordered the similar names list by dependents, listing the total dependent count across all versions of each package.
Our new similar names feature is available on npm, PyPI and Cargo. We have computed 12k similar name pairs for npm, 4k for Cargo, and 5.5k for PyPI.
We plan to keep iterating on our similar names calculations and to bring this information into our API and BigQuery datasets in the future. We hope this feature will help you to find the right packages that you are looking for!