We’re excited to announce that deps.dev now supports the Gradle Plugins
ecosystem, with over 15,000 new packages and 270,000 versions from
plugins.gradle.org now indexed and available.
How can I use the data?
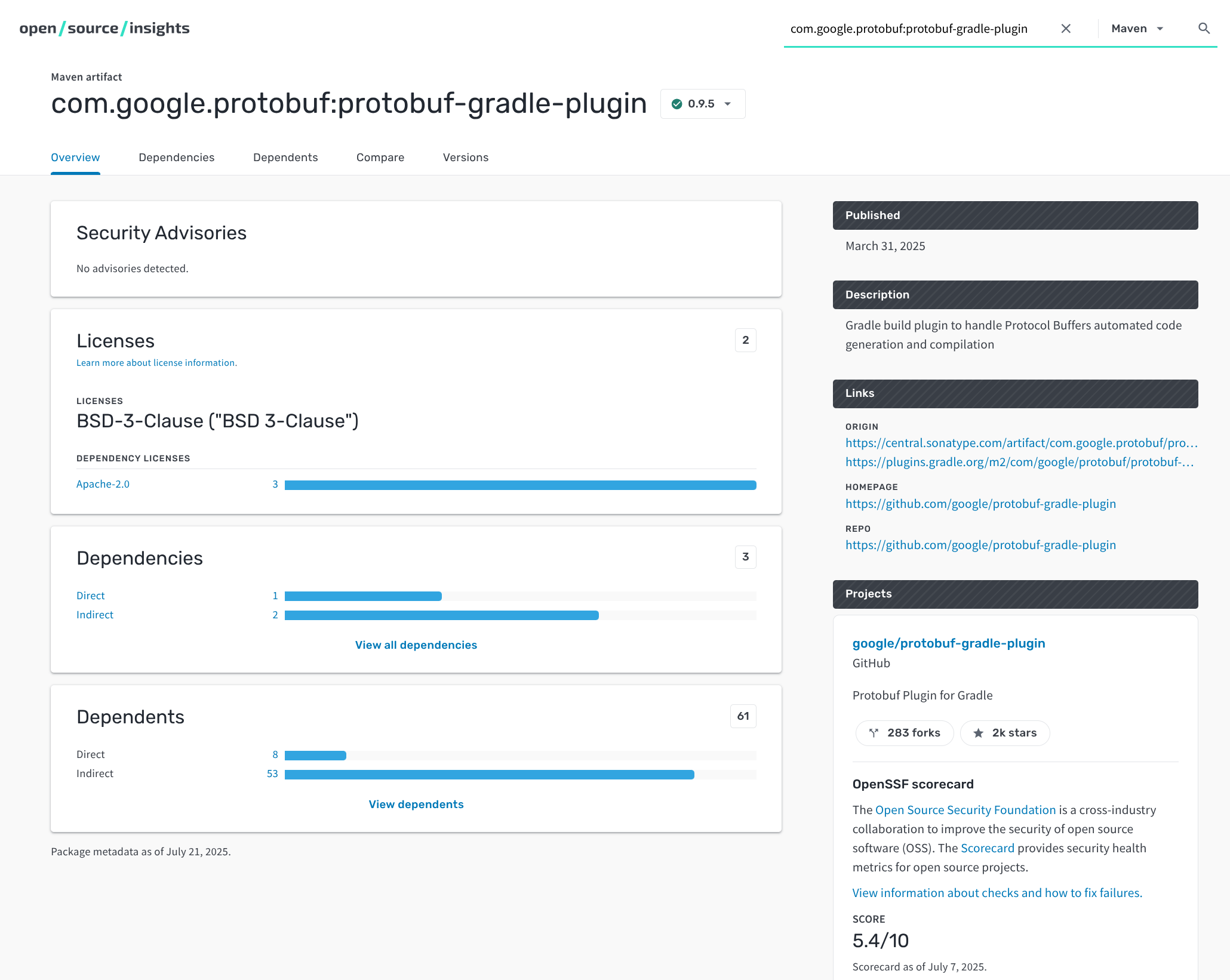
Screenshot of the info page for an example Gradle plugin package
Gradle Plugin support adds to deps.dev’s existing support of Maven Central,
Google Maven, and Jenkins Plugins. Gradle Plugins results can be accessed in the
same manner as for the existing Maven repositories through the website, API, and
BigQuery dataset.
Why does this matter?
Build tooling is a critical part of the software supply chain – vulnerabilities
in build plugins can be as dangerous as those in application-level dependencies.
By providing visibility into these plugins, deps.dev is one step closer to
giving developers a more complete understanding of their project’s security
posture.
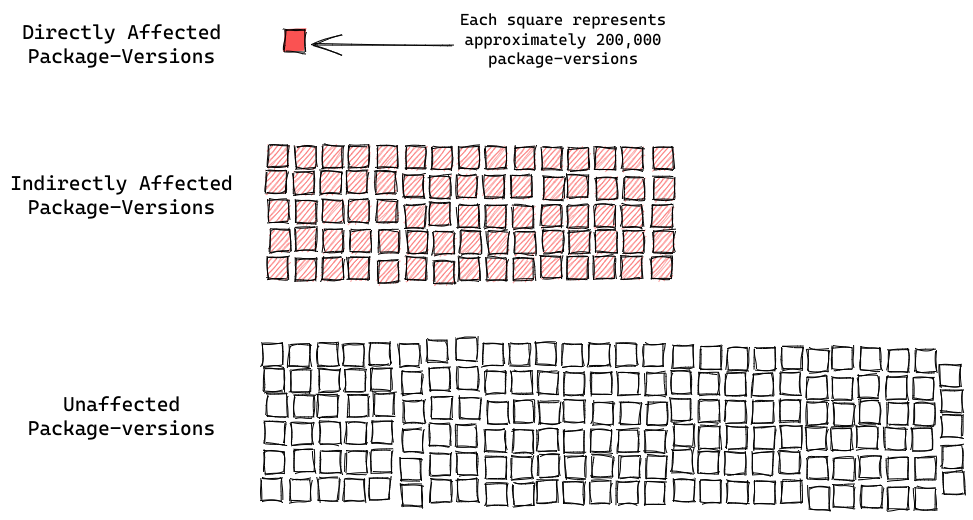
Our analysis reveals that approximately 2% of Gradle plugin versions have known
security vulnerabilities. This prevalence is notably higher than what we observe
across the broader Maven ecosystem (≈1%) and other systems like PyPI (≈1%),
underscoring that build dependencies can be a significant and concentrated
source of security risk.
If you have any questions or feedback please reach out to us at
depsdev@google.com, or by filing an issue on our
GitHub repo.
Hayden Blauzvern, Eve Martin-Jones, Google Open Source Security Team
We’re pleased to announce the creation of a new BigQuery public dataset, rekor. The rekor dataset is an easily-queryable mirror of the public good instance of Sigstore’s transparency log, Rekor.
Sigstore is an open source project for improving software supply chain security. The Sigstore framework and tooling empowers software developers and consumers to securely sign and verify software artifacts. For example, deps.dev uses Sigstore to verify the provenance of software published to upstream package registries.
Signing events are recorded in Rekor, an append-only transparency log. Software producers can verify metadata in the log, verifying that the recorded signature metadata was produced as expected when their identities or keys were used to sign artifacts. Software consumers rely on cryptographic proofs of log inclusion to verify that software artifacts are recorded to the log.
This dataset will allow open source supply chain researchers and other interested parties to gather aggregate data on how artifacts are being signed with Sigstore, answering questions like “what is the most common CI provider used to sign artifacts?” or “how many artifacts are signed each month?”.
Eve Martin-Jones, Max Fisher, Open Source Insights Team
I’m happy to announce that today deps.dev is launching support for RubyGems,
the Ruby package manager. We have 184k gems and 1.8 million versions available
through our API, website and BigQuery dataset.
Deps.dev already supports npm, Go, Maven, PyPI, Cargo and NuGet and we’re
excited to add support for RubyGems as another major open source package
management ecosystem. We hope that Ruby developers will be able to use deps.dev
to gain insight into the software they use and help tackle the ever-increasing
number of open software supply chain attacks.
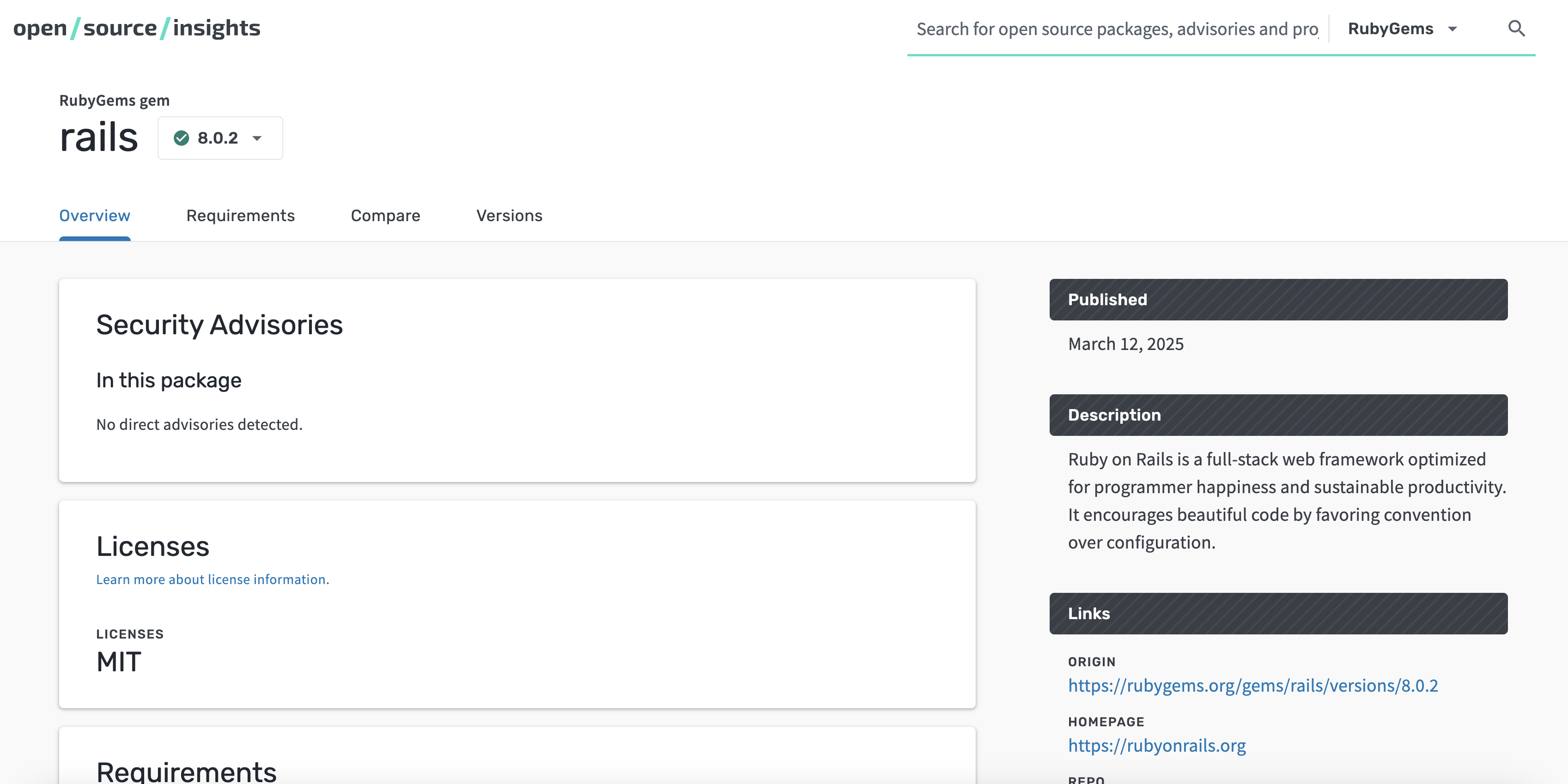
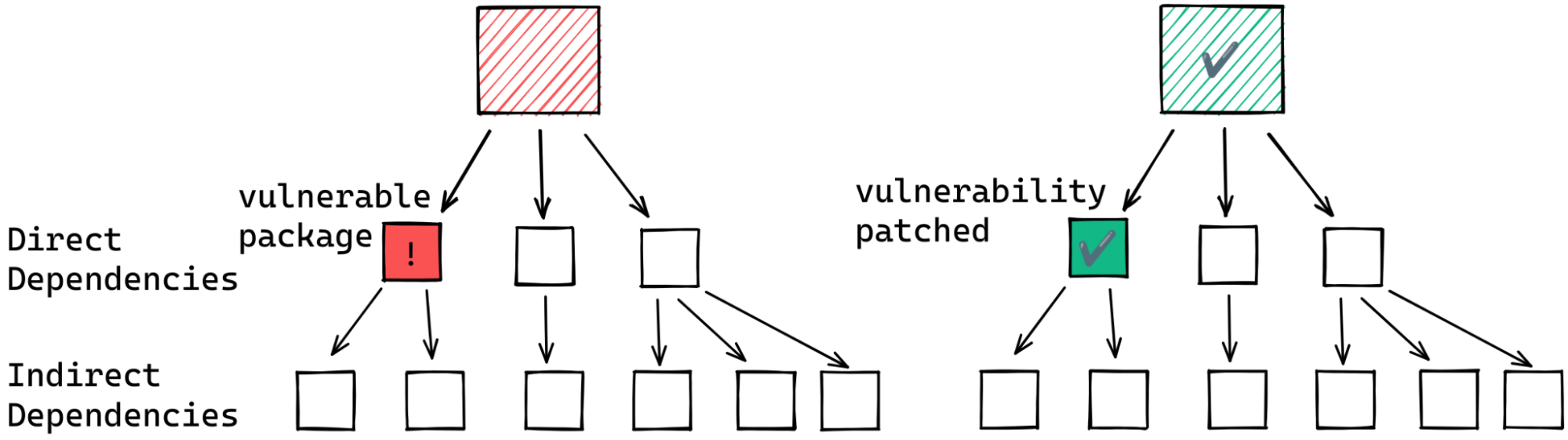
Advisories: You can check whether a gem is directly affected by an advisory,
and if so, whether there is an unaffected version you could use. For example,
compare versions
7.0.0 and 8.0.2 of the rails gem.
Hashes: You can use the Query API
endpoint to query for the name of
a mystery gem using its hash.
Version metadata: You can see gem metadata like license, publish date,
description and reference links.
Data is currently only served for gem versions with the default
platform “ruby”. In the future,
we plan to serve data for all gem versions regardless of platform.
We also plan to add support for RubyGems Sigstore attestations, which users can
use to verify the integrity of a gem version published to RubyGems. This
follows on from our existing support for PyPI digital
attestations and npm SLSA
provenance attestations.
We’d love to hear what you think about our RubyGems support. Get in touch via
email at depsdev@google.com or file an issue in
our GitHub repository.
Josie Anugerah and Eve Martin-Jones, Open Source Insights Team
We’re excited to launch our experimental base container image identification
API in deps.dev! The
base image identification API lets clients look up a published container image
by its chain
ID.
We have 730k unique images indexed so far (and counting).
The new OSV-Scanner v2
release leverages
this API to associate security vulnerabilities with specific base images in a
container image scan.
What is a base image?
A container
image is “a
standard unit of software that packages up code and all its dependencies so
that the application runs quickly and reliably from one computing environment
to another” All container images begin with a base
image that the image
author builds upon.
Images are typically created from dockerfiles, which contain a series of
commands that build the image when executed. A short dockerfile might look
like:
FROM alpine:latest
ADD my-program /
CMD ["/my-program"]
Fig 1. A short example dockerfile.
In this example, the FROM
command sets the base
image for this image to be alpine:latest. The ADD
command copies the binary
my-program to the images filesystem. The CMD
command sets the command
“my-program” to be executed when running a container from this image.
Base images like alpine:latest allow common instructions to be shared between
image authors. Rather than re-writing the instructions needed to set up an
alpine environment, any image author can use the FROM command to include the
base alpine image. Base images are also specified as a dockerfile/series of
executable instructions. For example, the instructions for alpine:latest
might look like:
To build an image, the container build tool executes the commands in the
dockerfile. First, it executes the commands specified in the base image,
followed by the custom commands in the image. When building the example image
above, the following commands would be executed:
Fig 3. The effective commands run for the short dockerfile in Fig 1. The FROM
line is replaced by the base image commands.
The output of the build process is a series of filesystem layers (where each
command produces ~one layer), along with additional metadata files such as the
image manifest and config files which provide an ordered list of the filesystem
layers identified by its hash. For example, the manifest file produced by
building the example image might look something like:
Fig 4. The layers produced by building the dockerfile in Fig 1. Instructions
that don’t produce a file system diff (eg. most CMD instructions) are commonly
excluded in the manifest.
Together, these build outputs constitute a container image which can be
distributed by a container registry. However, building an image is a lossy
process. The original instructions used to build the image (including what base
image was used) are not included in the layers and files the build outputs.
These instructions and the base image information are therefore also not
present in the images that get distributed.
How does knowing the base image help?
Not knowing the base image makes analyzing images for vulnerabilities
difficult. While we’ve been using a simple image as an example, in practice,
many images are built from multiple base images chained together. If you don’t
know which of these images introduced a vulnerability, it’s difficult to
remediate that vulnerability.
For example, suppose a user downloaded our example image from a container
registry and ran it through a vulnerability scanner like OSV-Scanner. They may
find that the second layer introduces a vulnerable package to the filesystem.
But if they don’t know whether that layer was created from the instructions in
alpine:latest or the instructions in the example dockerfile, it will be
difficult to remove the vulnerable package. Knowing where exactly a
vulnerability was introduced is crucial to remediating it.
How does the container base image API work?
As mentioned above, an image is made up of file system layers, a manifest file
and a configuration file. The manifest and config files don’t explicitly tell
us the base image of an image is. However they do provide an ordered,
content-addressed list of the layers.
A layer is an archive of added and deleted files. They can be content-addressed
by their diff
ID
(a hash of the decompressed archive). A sequence of layers in a particular
order can be referred to using a chain
ID.
The container base image API works by accepting an ordered sequence of layers
in the form of a chain ID and matching it to the chain IDs of popular base
images deps.dev has indexed. The API returns any image repositories the chain
ID matched to.
By producing the chain ID for every prefix of layers for your image and looking
them up in the QueryContainerImages API, you can identify what base image(s)
your image could be based on.
How can I use this?
The easiest way to try this out is by using the new OSV-Scanner v2 release
(blog) which leverages
QueryContainerImages to scan containers for vulnerabilities and attribute them
to layers.
osv-scanner scan image <image-name>
Example output from the osv-scanner scan image command.
If you’re just wanting to use the API to see what base image(s) your image
depends on, there is example
code
at the deps.dev repo that computes the Chain IDs from an OCI image tarball and
prints any base images reported by our API.
We’re also exploring improvements into the API such as ordering repository
results by popularity and including tags in the result. This is an experimental
API available in v3alpha, so we’d love to hear about any feedback you have. You
can file a GitHub issue at
github.com/google/deps.dev or email us at
depsdev@google.com.
Eve Martin-Jones, Google Open Source Security Team
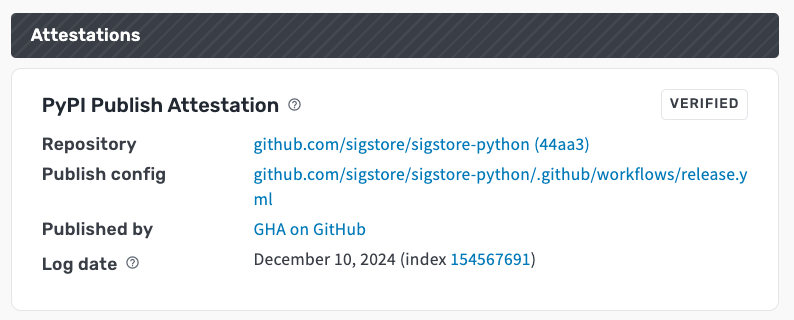
Digital attestations can be critical for preventing, detecting and analyzing security incidents. During the recent Ultralytics supply-chain attack responders were able to audit malicious activity during and after the incident because the compromised PyPI Ultralytics project was using Trusted Publishing and digital attestations.
We are excited to announce that deps.dev now serves PyPI digital attestations (alongside our existing support for npm digital attestations). You can view digital attestations for PyPI packages on deps.dev - for example, deps.dev/pypi/sigstore.
A screenshot of the Attestations panel for the PyPI sigstore package at version 3.6.0 showing a PyPI Publish attestation
PyPI recently announced support for maintainers to publish two types of signed digital attestations when publishing new package versions: PyPI Publish and SLSA Provenance attestations.
PyPI Publish attestations provide a minimal “implicit” digital attestation for packages via Trusted Publishing. Consumers can use the attestation to verify the integrity of a release published to PyPI, in particular:
That the release was uploaded via a Trusted Publisher
Which Trusted Publisher identity was used to publish the release (for example, a GitHub Actions workflow or a GitLab identity)
SLSA provenance is metadata about how a package was built and strongly links an open source package to the build system and source code used to create it. It is part of the SLSA framework for improving supply chain security. In a SLSA provenance attestation you can find:
The repository and commit at which the artifact was built
Details about the workflow used to create the artifact
PyPI has taken a big step toward securing the open source supply chain and it’s great to see this work paying off during security incidents like Ultralytics. For more information about digital attestations in PyPI see PEP 740. For an overview of digital attestation adoption across the PyPI ecosystem see Trail of Bits’ Are we PEP 740 yet? dashboard.
If you have any questions, feedback or feature requests, you can reach us at depsdev@google.com, or by filing an issue on our GitHub repo.
Eve Martin-Jones, Google Open Source Security Team
We’re pleased to announce that deps.dev has extended support for querying package versions by their upstream identifiers in our BigQuery dataset. This blog post explores the problem of multiple identifiers for package versions and describes how supporting additional identifiers allows deps.dev users to query for versions more easily.
Knowing what name and version string to use when referring to an open source package can be more difficult than you might expect. Different ecosystems have different rules that specify how you should refer to a package version. For example, in Go module names are case sensitive, while in npm package names must be lowercase today (but not historically).
In many open source ecosystems, there are multiple valid identifiers that map to the same version of a package. Let’s take a look at the PyPI flask-babel package to see how this plays out in practice. Say I wanted to depend on this package from my own Python project. What name should I use to import it?
Diving into the metadata for the latest version of the package (4.0.0 at the time of writing), I can see that the name given in the PKG_INFO file for the flask_babel-4.0.0.tar.gz release is flask-babel:
A screenshot of the PKG_INFO file for the flask_babel-4.0.0.tar.gz release with the 'Name' field highlighted
This is consistent with the name on the pypi.org package page.
However, if we look at the PKG-INFO file for an older release — 2.0.0 —, we can see the package being referred to by a different name Flask-Babel:
A screenshot of the PKG_INFO file for the Flask-Babel-2.0.0.tar.gz release with the 'Name' field highlighted
At this point we’ve seen this package referred to by two different names: flask-babel and Flask-Babel. Which one is correct?
In fact, they both are. According to the PyPI name normalization rules a package name “should be lowercased with all runs of the characters ., -, or _ replaced with a single - character”. By those rules, both flask-babel and Flask-Babel normalize to the same string: flask-babel (as do many other names like FLASK-BABEL, flask_babel or FLASK._-_.babel).
So in PyPI there is no single “correct” name for the flask-babel package. Any name that normalizes to that string can be used with the pip tooling to install that package. For example, the three following commands are equivalent:
This is also true of version strings. While 1.0.0.0, 1.00.0.0 and 1.0.0 are different strings, according to the Python Packaging User Guide: Version specifiers they all refer to the same version.
Allowing users to refer to packages and versions under multiple identifiers can limit typosquatting attacks (if a user accidentally types Flask_Babel they’ll still get the expected package version). But it can also make some types of analysis tricky. For example, if we want to know every version of flask-babel that exists we need to look at all the releases whose name normalizes to that string. Similarly, if we want to know every package that depends on flask-babel, we need to search the dependencies of every other PyPI package for any string that normalizes to flask-babel.
To make these aggregations sensible and efficient, it often makes sense to store information keyed by a package’s normalized name/version. That way, we can easily aggregate metadata and dependents/dependencies across package versions without having to normalize the data each time.
For platforms that serve data about open source packages, this underlying normalization is generally hidden from users. For example, pypi.org redirects different valid spellings of a package name to the right underlying package (see flask-babel, Flask-Babel and FLASK.-.babel). Similarly, the deps.dev API normalizes package names in user requests so that multiple identifiers can be used to refer to the same package (see flask-babel, Flask-Babel and FLASK.-.babel).
This approach works fine in places where name normalization can be performed on-the-fly by the server (like a website or api). However, normalization can become tricky in places where packages need to be keyed by a single name — like a BigQuery dataset. While normalization is necessary in these cases (because of the aggregation requirements previously mentioned), it can be surprising to users. Especially if the normalized name differs from the name the package is commonly known by.
Let’s look at the case where the normalized name of a package version differs from its name on pypi.org — the Pygments package. If you’re looking at the Pygments package on pypi.org, but running the query:
SELECT * FROM deps-dev-insights.v1.PackageVersionsLatest
WHERE System="PYPI" AND Name="Pygments";
returns no results, it’s a reasonable assumption that deps.dev doesn’t know about the package (what’s actually happening is that the deps.dev BigQuery keys that package by its normalized name, pygments).
This is a problem because it’s fairly common for the canonicalized name to differ from the name given in the package metadata (this is true for 75558 or 13.33% of PyPI packages).
For that reason, we’ve introduced a new UpstreamIdentifiers column in BigQuery that contains the pre-normalized name and version strings. Using this column, we can query by any upstream name/version string that a package version uses to refer to itself:
SELECT * FROM deps-dev-insights.v1.PackageVersionsLatest
WHERE System="PYPI" AND "Pygments" IN UNNEST(UpstreamIdentifiers.PackageName);
There are a few caveats. Firstly, it’s possible that not all versions of a package will be returned by this query. Only those versions that refer to themselves by that name will appear in the results.
Secondly, not every string that normalizes to a name will be included in this UpstreamIdentifiers column. There are many possible strings that normalize to e.g. pygments and enumerating all of them isn’t particularly useful. Only identifiers that are encountered upstream during a package version refresh are included.
Despite these caveats, we hope that this additional column will allow our users to more easily map the identifiers they might see upstream to our BigQuery data. The upstream identifiers are also available via the v3alpha API. Additionally, deps.dev provides a Go package for parsing, order and matching versions as defined by Semantic Version 2.0.0 that supports extensions and quirks implemented by a number of package management systems. It can be found at github.com/google/deps.dev/util/semver.
If you have any questions, feedback or feature requests, you can reach us at depsdev@google.com, or by filing an issue on our GitHub repo.
Jess McClintock and John Dethridge, Google Open Source Security Team
Security usability is hard — security best practices often add further toil on developers, to the point where usability and security are often considered as direct tradeoffs. But they don’t have to be. There are many fantastic analysis tools and platforms for developers who want to audit their transitive dependencies or vendor a third party package. We aim to make this process less involved by running analyses centrally and making results directly available to open source consumers without any additional steps for maintainers.
We are excited to have added Capslock results for Go packages. Capslock is a Google open source tool that identifies “capabilities” that packages have — for example, the ability to read files, or to send and receive data on the network. This will provide added visibility into the behaviors of Go packages, to assist in choosing appropriately scoped dependencies, understanding what packages are doing under the hood and noticing when dependency updates require more powerful capabilities. Our aim here, as with deps.dev as a whole, is to help those choosing and using open source packages to make well informed selections based on as much security-relevant data as possible.
A difference that makes a difference?
Our analysis found that less than 2% of version updates for packages will introduce a new capability requirement. This makes sense, since the set of capabilities required by a package will usually be established by its initial behavior, and if a dependency adds new capabilities, that can be a signal for maintainers that the change is more interesting (or, perhaps, the change warrants further investigation).
We divide these results according to whether the standard library was called directly from the analyzed package or via a transitive dependency. Some capabilities, such as those involving the network, are more likely to be used directly than via a transitive dependency. Interestingly, a whopping 9% of Go packages have a transitive dependency using os/exec!
Capability Analysis for Go
Capslock was launched last year as a CLI to analyze the callpaths of Go packages and report on the privileged capabilities that are accessible. If a package unexpectedly adds a new capability in an update, or uses capabilities that aren’t required for its operation, this can be a risk indicator about the codebase. Capabilities can also be a useful signal for verifying that a package does what is expected — a well designed package should itself require minimal privileges, and allow objects and interfaces like those in io/fs to be passed in that encapsulate privileged capabilities.
Capslock results on deps.dev include the list of capabilities that have been identified in each particular version of a package. Note that the analysis results are build specific, so functions that are only included when a package is built for a specific operating system might not appear in our reports. You can find more details about this analysis in the Capslock documentation.
Today we are launching Capslock capability results for Go packages on deps.dev. This will be our first step in making capability data more widely available to open source consumers.
Today we’re adding artifact URLs to our
v3alpha/Query endpoint. Since the
deps.dev API was launched in April 2023, deps.dev
has supported mapping artifacts to package versions using content hashes.
From user feedback, we discovered that some of the results were surprising. To
address this, we’re providing more information about why a hash matches a
package version through a new artifacts field in the Query endpoint response.
This artifacts field contains the URL of the artifact the hash was calculated
from.
This is a breaking change to the v3alpha/Query endpoint. As mentioned in the
v3 API blog post, v3alpha is intended for
experimental features and v3 for stability. Features that become stable in
v3alpha will eventually be added to the v3 API as a non-breaking change. If you
have a critical application depending on the deps.dev API and are still using
v3alpha, consider migrating to v3.
In April 2023, we launched the first public version of the deps.dev API,
v3alpha, complementing the deps.dev website and BigQuery dataset as a
new way of exploring our software supply chain data. Since then, the API has
served billions of requests, enabling applications like
providing a richer view of SBOM data in GUAC or
reporting dependency licenses in OSV-Scanner. Today, we’re adding a few of
our most frequently requested features, along with a new version of the API
that comes with a stability guarantee.
A new stable version
When we launched the first public version of the API, we named it v3alpha to
indicate that it might change over time. In practice, we haven’t needed to make
any incompatible changes to it since launch. Today, we’re formalizing our
approach to API stability.
First, we’re launching a new version, v3, that comes with a stability
guarantee: we will never make incompatible changes to it. It also comes with a
deprecation policy: if and when we deprecate the API in favor of a newer
version, we will give at least 6 months notice. Deprecations will be announced
on this blog, on our documentation site, and on our GitHub repo. The
v3 API has almost exactly the same structure as v3alpha has had, with only a
few small tweaks to fix inconsistencies and set it up for
planned—compatible—changes, and is also available via gRPC or HTTP. We
recommend that most users migrate to it.
Second, with v3 providing a stable option, our existing v3alpha API can be a
bit more experimental. This means that most new features will start out in the
v3alpha API, possibly change in incompatible ways in response to user feedback,
and eventually graduate to the v3 API.
Batch request support
First among the experimental features we’re adding to the v3alpha API is a
highly requested one: batch support. Many applications currently require making
hundreds of API requests for a single user task—such as fetching licenses and
security advisories for all your dependencies—which can be cumbersome. With
our new GetVersionBatch and GetProjectBatch endpoints, you can instead make a
single request containing a batch of identifiers, and get the results in a
paginated response.
Purl support
The next new experimental feature is also one requested by users: support for
fetching package- or version-level data by purl. Purls, or package URLs,
are widely used identifiers for packages and versions from a number of
ecosystems, including the six that we currently support. By adding purl support
to the API, we hope to lower the barrier to integrate it into existing
workflows. Combining our two new features, we’re also adding an endpoint for
requesting batches of versions by purl.
But wait, there’s more!
In addition to these brand new features, we’re also filling a few gaps. You can
now find packages with similar names, previously launched on the deps.dev
website, using the GetSimilarlyNamedPackages endpoint in the v3alpha API. We’ve
made OSS-Fuzz data available from the GetProject endpoint in both the
v3 and v3alpha APIs. We’ve also added more data showing how package versions
and projects relate to each other, whether by metadata or by SLSA attestations,
so users can decide whether the link is trustworthy for their application. SLSA
attestations are now also verified by us.
To get started using any of the new API features mentioned in this post, check
out the documentation, or visit our GitHub repo for code examples
and the gRPC service definition.
Francois Galilee and Laurent Simon, Open Source Insights Team
In this post, we explain how dependency resolution works in package managers,
with the npm ecosystem as an example. We also explain how it directly affects
the accuracy of SBOMs you generate and ingest.
Let’s take the package d3 as an example.
Version
d3@7.8.5
requires 30 dependencies in its npm
package.json. How many different Node.js
applications respecting these 30 requirements may be generated? One? Quite a
few actually: at the time of writing, there are ~1.9X10^81. That makes as many
possible SBOMs for this application as the estimated number of atoms in the
universe.
Composition in package managers
Open source ecosystems in general thrive on sharing and reusing components.
When a developer builds an application, they compose their application’s code
with multiple components created by other developers, that in turn may rely on
multiple components created by other developers. To facilitate this
composition, each ecosystem provides tools to install libraries and
applications.
Among them and of particular interest to us is the dependency resolver, that
goes beyond direct dependencies and ensures that transitive requirements are
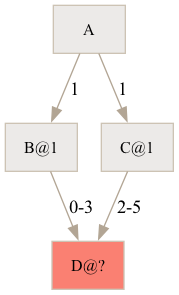
satisfied. For example if an application A depends on two libraries B and C
that both in turn depend on a library D with conflicting requirements, which
version of D should be chosen?
A diagram containing a package A with a requirement of 1 on packages B and C, which in turn have requirements 0-3 and 2-5 on package D respectively.
Let’s dive deeper. We will focus our discussion on npm as a concrete example in
the rest of the post. The insights are typically applicable to other
ecosystems.
Dependency requirements
In the npm ecosystem, npm registry is the de
facto public registry and npm the de facto
associated tooling. CLI alternatives to npm exist, including
yarn and pnpm.
Developers express their dependency requirements in a manifest file
“package.json”, specifying a package and a set of acceptable versions for each
package. For example, let’s create an application with four dependencies:
This manifest declares four dependencies named “d3-time”, “d3-array”, “array”,
and “color”, each with a corresponding version range. For example, “d3-time” is
declared with the constraint “^3” which means that any 3.x version may be
installed. (More information about version declarations are in the
official documentation). In addition to version
set requirements, packages can be aliased, as illustrated by “array” and
“color” that are aliasing “d3-array” and “d3-color” respectively.
Dependency resolution
Given this set of dependency requirements, the ecosystem tooling selects and
installs the versions that it deems adequate (often the latest version of the
matching set) to create an application. This process is referred to as
“dependency resolution”. The selected packages are physically installed as a
file tree for npm, so that Node.js imports them at runtime. Below is an example
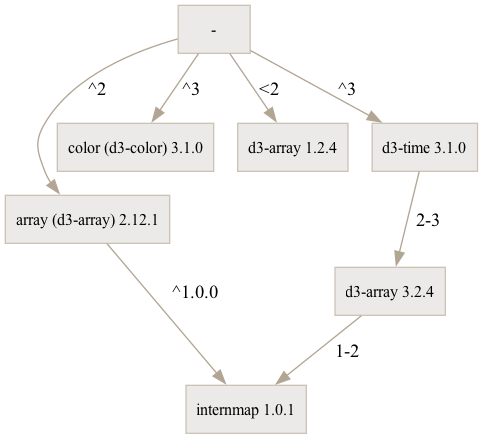
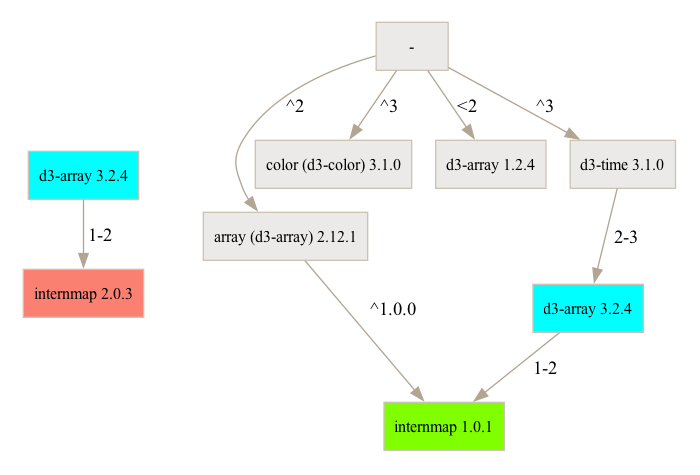
of an installation by npm@6.14.13 for the former manifest:
$ npm -v && npm install && npm ls
6.14.13
+-- array@npm:d3-array@2.12.1 // d3-array@2.12.1 installed under an alias.
| `-- internmap@1.0.1
+-- color@npm:d3-color@3.1.0
+-- d3-array@1.2.4 // d3-array@1.2.4 installed at the root.
`-- d3-time@3.1.0
`-- d3-array@3.2.4 // d3-array@3.2.4 installed locally, shadowing the root.
`-- internmap@1.0.1 deduped
In the snippet above, we note that “d3-array” is installed multiple times
with different versions:
Once under the alias “array” for the main application’s code, as
“d3-array@2.12.1”
Once for the main application’s code, as “d3-array@1.2.4”
Once for “d3-time”, at version “d3-array@3.2.4”. This means “d3-time”
will use version 3.2.4.
If we use different tools to install from the same manifest file, they may
install different dependency versions. On our example manifest file, npm, yarn,
and pnpm produce different installations:
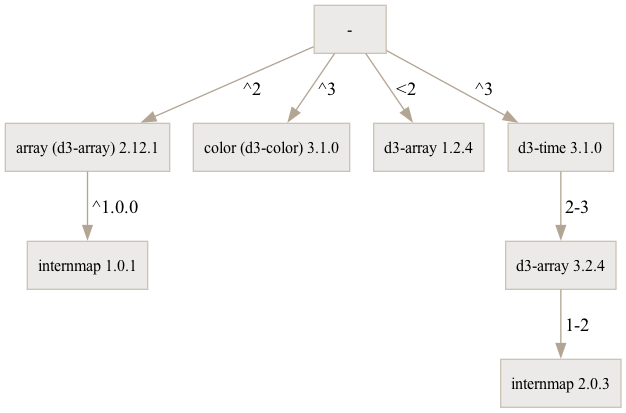
A resolution result for the manifest above using npm 6.14.13 or at version 9.8.1 hoisted.A resolution result for the manifest above using yarn 1.22.10 or npm 9.8.1 nested.A resolution result for the manifest above using pnpm 8.6.9.
All three dependency resolutions are valid and are among the set of graphs that
satisfy the constraint requirements. Other factors besides the tool chain can
affect the resolution. For example, the time: if we install this manifest
today, the result may be different from the installation we made yesterday:
version resolutions change as new (dependency) package versions become
available or deleted from the npm registry.
Downstream consumers control the composition
It is worth noting that the composition (aka version resolution) is triggered
by the downstream user who creates an application. In other words, dependency
packages (libraries) are oblivious to the composition. They express
requirements for their own direct dependencies as abstract strings (like
“d3-time@^3”) that define the set of functionally compatible versions. But it
is the tooling run by the downstream user creating the application that selects
and installs a concrete version from among this set. The selected version may
be different from the version that would have been selected by the dependency
package itself, as it is made in a different context, using different tooling,
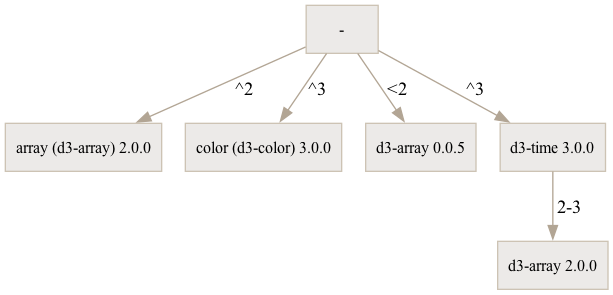
at a different time. For example, d3-array@3.2.4 resolves differently in two
different contexts:
The dependencies of d3-array 3.2.4 as a stand-alone library and within an application. In both cases, the dependencies were resolved by npm 9.8.1 using the hoisted strategy, but produce a different set of dependencies.
It is impossible for the maintainer of a package to enforce dependencies’
versions in downstream users’ applications. For example, they may try to “pin”
their own dependency requirement to a specific version, in the hope to force
downstream users to use that particular version transitively. But this still
can be overruled by a downstream user by:
Using an
overrides
directive to override the dependency.
Using a custom alias.
In the example manifest, if “d3-array” was defined as an alias for
“d3-color”, npm would install d3-color in lieu of d3-array to the
surprise of the library.
Furthermore, pinning a dependency (by a strict requirement or by providing a
bundle) in a library is
considered bad practice
because it prevents downstream users from upgrading the dependency
independently if they need to (to resolve a vulnerability for example).
As we have seen in the first part of this blog post, packages that are
libraries have dependencies, but their versions are resolved by the final
application, not the library itself. When an SBOM is generated by the library
maintainers at the time of publication, the dependency resolution happens in a
different context from the context in which the final application is built
(package manager CLI version, available packages on registry, etc). As a
result, the dependencies listed in a library SBOM are irrelevant for downstream
applications.
Conclusion
In this post, we saw that one set of requirements yields a vast number of
applications: the decision on which concrete dependencies are installed lay in
the hands of consumers. So library SBOMs cannot list the exact dependency used,
but application SBOMs can. Furthermore, the composition involves dependency
resolution that relies on complex algorithms. Given the space for error and the
nuances of dependency resolution, it might be beneficial to develop tooling to
ensure that the application SBOM describes faithfully what has been installed.
As part of an internship project, we experimented with finding dependencies that
are both important and have few maintainers, based on their public source code
repositories and deps.dev dependency graphs.
Modern software development heavily relies on open source libraries to reduce
effort and speed up innovation. However, alongside the many benefits,
third-party open source libraries can introduce risk into the software supply
chain, and modern ecosystems make it easy to end up pulling in tens, if not
hundreds of dependencies. Given limited resources, which dependencies should
developers focus on to mitigate the risk of supply-chain attacks? Which
dependencies might be exposed to more risk of
single points of failure? In other words, we want to
not only consider the likes of numpy, but also
explore the well-hidden 30LoC single-author packages that everyone depends on.
Dependency graphs
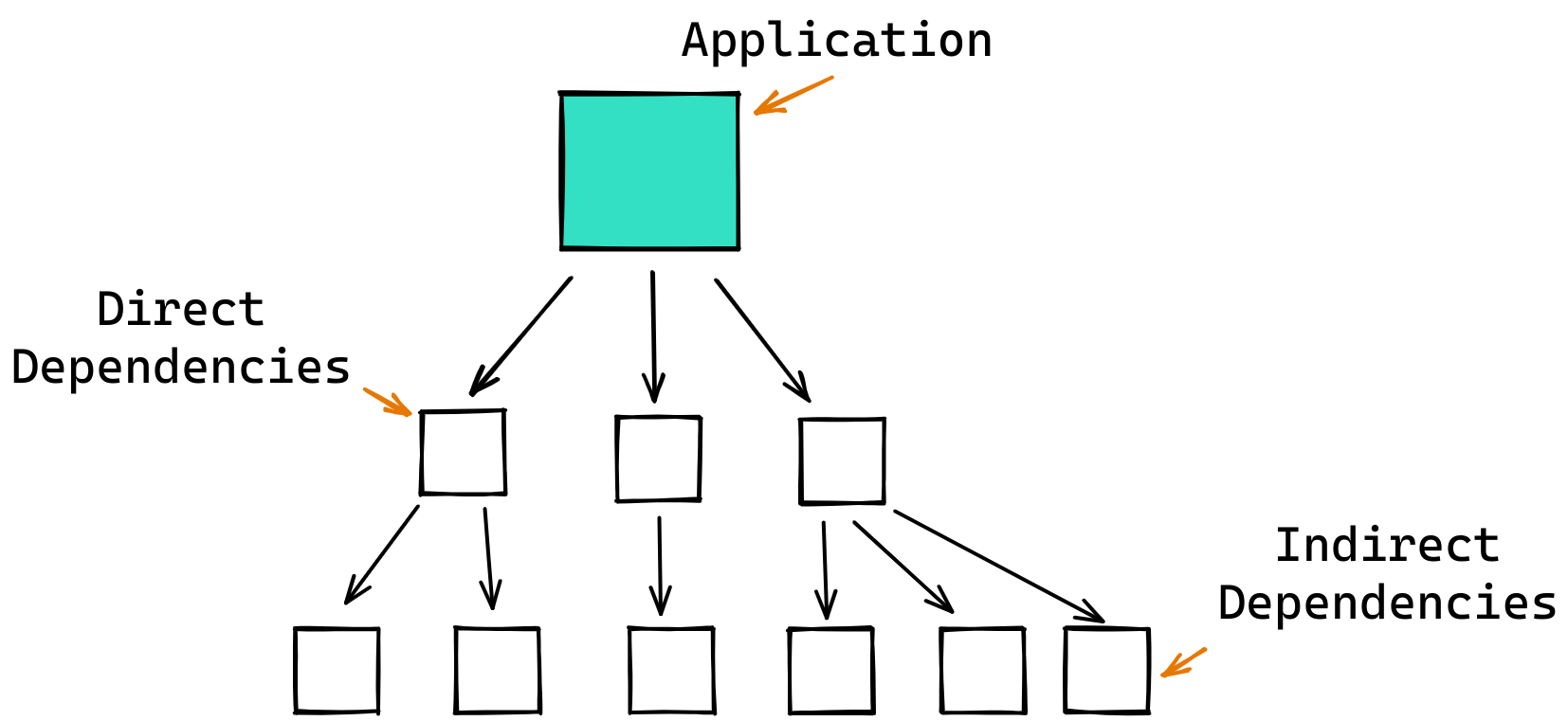
Deps.dev provides resolved dependency graphs for packages in several ecosystems.
These graphs can be complex and can include thousands of direct and indirect
dependencies.
A package’s deps.dev page (for example react) also includes
information on the package’s dependents (the open source packages that include
the package as a dependency). This information can help us narrow our focus to
important packages - those with many direct or indirect dependents. The number of
dependents is a good starting metric, and it is already used as part of one
prior importance measure for repos called the
OpenSSF Criticality Score.
But which of these important packages might be susceptible to the risks of a
single maintainer?
Dependency graphs are more powerful with more data
Input data: dependency graphs and authorship data
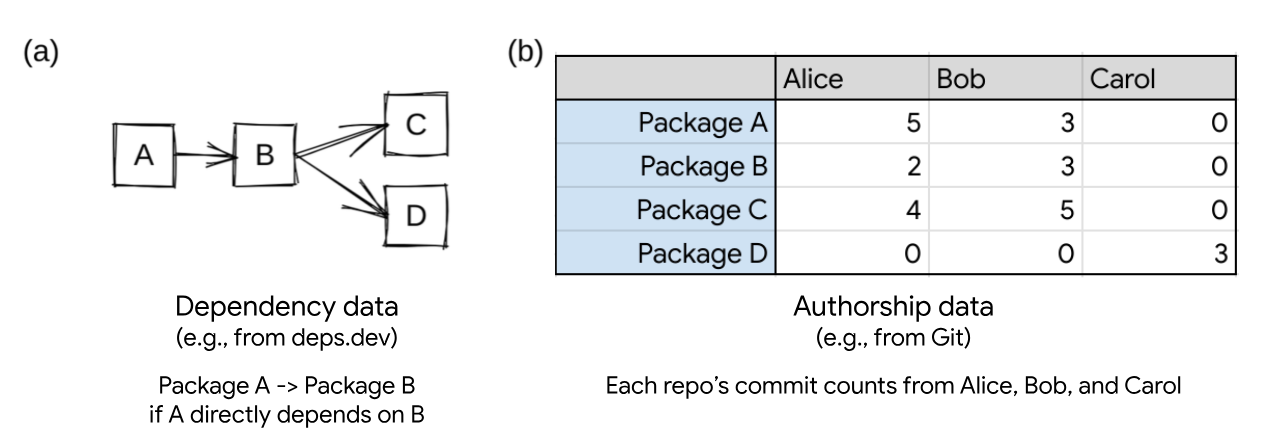
Let’s look at a hypothetical example dependency graph, and see how both the
package dependency graph and contributor commits to an associated repository
can be combined to help developers focus on
interest-worthy packages in their supply chains. Suppose that all of a
developer’s open source software (OSS) dependencies can be mapped to four repos:
A, B, C, and D. This is shown graphically in figure (a).
If we only consider the dependency data, C and D are the most important packages
in the ecosystem. They have the largest number of dependents. If an attacker
were to introduce a vulnerability in either C or D, more packages within the
ecosystem will be compromised than if a vulnerability is introduced in A or B.
Similarly, if B were to become unmaintained or no longer updated, it could block
the adoption of any vulnerabilities fixed in C or D.
In our example case, we consider not only dependency information, but authorship
information as well (shown in figure (b)), derived from source code commit information.
In this case, a special pattern emerges: repo D is solely authored by Carol,
while A, B, and C are all authored collaboratively by Alice and Bob.
When we consider this commit information, repo D becomes quite interesting
because it could represent a higher level of risk. All the work of securing repo
D, including coordinating security upgrades, falls to a single developer. In
general, it is good to have more eyeballs reviewing changes (“Linus’s
law”), or to have additional
developers performing upkeep.
In other words, repo D seems important because its authorship is unique and has
multiple dependents (both A and B). If we were to rank these packages in order
of importance for the supply chain, we could say that D > C > B > A. But is
there a way to compute this?
Modeling our intuition
Given our intuition, how do we concretely model a ranking of repos when we might
have thousands of repos and tens of thousands of authors? To put it in computer
science terms, we can map this to defining a scalable node importance score
(“node centrality”) and a way to
construct a graph using both dependency and authorship data.
Looking at our original dependency graph (figure (a)), imagine a walker is
placed on a random node and always travels in the direction of the arrows. The
walker randomly chooses an arrow to follow; if there are no arrows to follow,
the walker stops. 50% of the time the walker will end up at C and 50% of the
time the walker will end up at D. This “random walk” notion of node importance
yields C and D being the most important nodes in the graph. Intuitively, C and D
are the “most upstream” nodes and attacking them will have the highest impact on
the ecosystem, and edges in the graph represent the delegation of security risk
and best practices. The more upstream a node is, the more repos have delegated
their risks to the node.
Augmented Dependency Graph
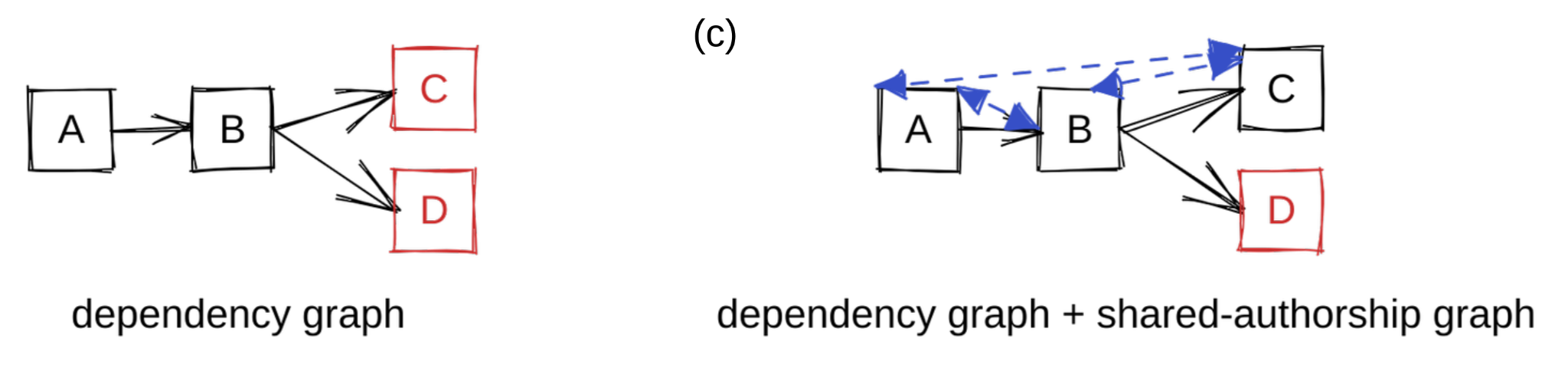
Let’s play with the concept of A, B, and C being related to each other because
they share their distribution of authors. The natural way to model relationships
in a graph is to add edges. We take a simplistic assumption that when repos
share authors, they tend to have similar security practices and quality. To
model this similarity we add bidirectional edges among all pairs in A, B, and C.
This gives us a new graph that not only takes into account dependency
information but also authorship information (figure (c)). Reusing our random
walker analogy, it is possible for the walker to reach D from any other node,
but once our walker is at D, it can no longer travel to another node. We see D
as the most important node in the graph: any random walker will eventually land
in D with 100% probability and be unable to escape.
The above argument captures our intuition to use the well-known
PageRank algorithm as the measure of
node importance. PageRank models a walker starting randomly choosing edges to
follow in the graph. The more often a node is visited, the higher its
importance. By adding shared authorship edges to the dependency graph, PageRank
tends to highlight single point of failures in the graph.
Applying to real data
We expanded upon this idea and added weights to the edges in a
Python implementation.
Then a test run was performed on a sub-ecosystem of our open source usage (a
graph of ~500 nodes and ~10k edges). We were able to confirm the general trend:
using source code commit data highlights important packages with potential
single point of failures better. Let’s take a closer look at a small case study
from our analysis that includes the following four packages:
golang/protobuf
adds support for protocol buffers in Go. Although it has been deprecated,
it is still alive and healthy. It has a variety of contributors.
josharian/intern
is a Go library to store the same strings in the same memory location. It
has widespread usage and is largely written by a single person.
numpy/numpy is a very popular numerical
library for Python. It is active and healthy, with many contributors.
google/go-cmp is a
utility library to compare values for testing in Go. It is popular and
largely written by a single person.
Here are the relative PageRank ranks of these four packages before and after
introducing authorship data:
Rank only w/ Dependency
Rank w/ Dependency + Coauthorship
golang/protobuf
1
2
josharian/intern
2
1
numpy/numpy
3
4
google/go-cmp
4
3
Table: Ranks of packages before and after introducing shared-authorship data;
lower rank means higher relative importance.
Notably, josharian/intern and google/go-cmp have fewer contributors than the
other two packages, and thus rank higher when we consider both dependency and
co-authorship.
More can be done with deps.dev
Deps.dev provides data to enable developers to perform data-driven decisions to
secure their supply chains. On top of deps.dev, developers and researchers can
supply additional data to customize the packages they focus on. We showed that
using source code commit data we can additionally identify potential
single point of failures in the supply-chain. All of the dependency data mentioned is
publicly available via the deps.dev API
and BigQuery datasets, while authorship data can
be obtained from the source code repositories associated with the packages.
Open source provides a wealth of data, and we welcome research ideas related to
network analysis or general data science that can help unlock new insights about
this important resource. If you have any research ideas or feedback, please open an
issue or contact us at
depsdev@google.com.
This work was performed as part of a Google internship program. If you’re
interested in working on open source security, we encourage you to apply to Google’s
internship program!
The deps.dev team has been thinking of ways to help you find the
right package, so we’re excited to launch the similar package names feature on
the deps.dev website! These similarity results are available for three open
source ecosystems: npm, PyPI and Cargo.
Screenshot of deps.dev showing packages with names similar to jost.
We are currently calculating the following forms of package name similarity:
Packages may have coincidently similar names due to the large number of packages within the ecosystem, but there are other reasons two packages may have similar names:
The packages may be intended to be used for different variations of a
language (jest is similar to
@types/jest)
The packages may provide functionality of the same category
(rson is similar to
bson and json)
One package may be named in homage to another more popular package
(redrx and redux,
jost and
jest)
A package may be intentionally named to confuse users, an attack category
known as typosquatting (reacy is similar to
react)
We have found that combining similar name calculations with a popularity metric
(such as dependents or downloads) helps to narrow down the noise. In
particular, prioritizing similar name pairs by dependents helped to reduce
uninteresting results. When we calculated similarity for all possible package
pairs, we observed a lot of noise; a lot of packages were similar to each other
for no reason other than that there are so many packages in each ecosystem, and
so few short or memorable names. For this reason, we calculate similarity only
to the most popular packages within each ecosystem, which led to more
meaningful results. And to make the results even more useful, we’ve ordered the
similar names list by dependents, listing the total dependent count across all
versions of each package.
Our new similar names feature is available on npm, PyPI and Cargo. We have
computed 12k similar name pairs for npm, 4k for Cargo, and 5.5k for PyPI.
We plan to keep iterating on our similar names calculations and to bring this
information into our API and BigQuery datasets in the future. We hope this
feature will help you to find the right packages that you are looking for!
Deps.dev is continually adding new features to help developers assess the
security of open source projects and the risks posed by adopting them as
dependencies. Today, deps.dev is excited to announce the integration of data
from projects tested by the OSS-Fuzz
service. This new integration will provide
users with a signal that the maintainers of a project are actively maintaining
good security practices — including preventive measures — to safeguard the
project from major vulnerabilities.
Fuzz testing,
or fuzzing, is an automated software testing technique that involves providing
random data as input to a program to find bugs that might not be found by other
testing methods such as manual or unit testing. To developers considering using
an open source project, fuzzing provides a positive signal about the security
posture of that project: it shows investment from maintainers and ongoing work
to discover and mitigate vulnerabilities.
Google’s OSS-Fuzz is a free service that continuously fuzzes critical open
source projects. Its fuzzing runs all day, every day, and an individual project
may be fuzzed more than once in a 24-hour period to catch new bugs introduced
with code changes as soon as possible. As of July 2023, OSS-Fuzz has helped
identify and fix over 9,600 vulnerabilities and 30,600 bugs across more than
1,000 projects, including widely used projects such as
netty and
spring-framework.
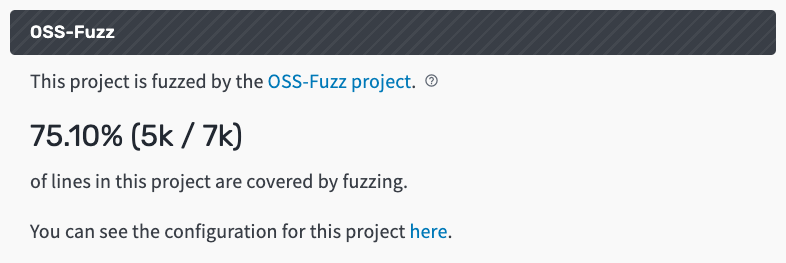
Deps.dev now tells you whether a project is fuzzed with OSS-Fuzz and, if so,
the percentage of lines of code covered and the configuration details for the
project, which show how thoroughly and in what way the project is fuzzed. For
example, google/leveldb’s page on
deps.dev shows that 75.1% of
the project is fuzzed, and links directly to the configurations in the OSS-Fuzz
GitHub repository for those who want to dig deeper into the details of how the
project is fuzzed:
Screenshot of deps.dev OSS-Fuzz UI for the google/leveldb project
We are pleased that this integration will help our users to make more informed
security decisions and will highlight the investments that maintainers have
made into their project’s security. To get started checking out the fuzzing
data for your favorite project, just navigate to the project’s page on
deps.dev!
Open Source Software (OSS) allows developers to share reusable parts of code
across projects, teams and organizations. As a result many thriving ecosystems
of interdependent OSS packages have developed. Many OSS packages depend on other
OSS packages to function.
We compute a full set of transitive dependencies for each version of each
package, and we call this the “dependency graph”. This data is available on our
web site,
API, and
BigQuery dataset. We
also compute the inverse of these dependency graphs, providing the full set of
versions that depend on any given version, and we call these “dependents”.
The set of packages that depend on a given package is useful for a number of
reasons. This blog post demonstrates how to fetch all the dependents of a
package within the deps.dev dataset using BigQuery.
Why do we need dependents?
There are various uses for the set of dependents of a package.
For example, the number of the dependents—direct and indirect—may
indicate the level of interest and adoption of a package. Well known
popular packages such as react or
gopkg.in/yaml.v3
have tens of thousands of dependent packages published in their
respective package management systems. Sorting packages by dependent
count can help identify some of the most critical packages within OSS
ecosystems.
Additionally, when a vulnerability is discovered in a package its set of
dependent packages is highly valuable. It provides insight into the scope of
vulnerability across an ecosystem. In some cases the dependents of the affected
package may need to act to help propagate a fix through the software supply
chain to end users. Access to dependent sets provides a means to identify such
packages.
Finally, OSS maintainers can also benefit from being able to identify the many
consumers of their packages and better understand how and where their package is
used. For example this information may help prioritize future work on their
package.
Sample queries
Let’s dive into some BigQuery examples. These samples will select the packages
that depend on gopkg.in/yaml.v3, but it is easy to adapt them for any other
package. Currently the full set of dependents for a given package can only be
accessed via BigQuery.
All dependent versions
Our first example fetches a list of all versions of all packages tracked by
deps.dev that depend on the Go package gopkg.in/yaml.v3 version v3.0.1.
SELECT
Dependent.System,
Dependent.Name,
Dependent.Version
FROM
`bigquery-public-data.deps_dev_v1.DependentsLatest`
WHERE
System = 'GO'
AND Name = 'gopkg.in/yaml.v3'
AND Version = 'v3.0.1';
Currently dependent versions
The previous query fetches all versions of all packages that depend on
gopkg.in/yaml.v3 v3.0.1. Multiple versions of some packages will often be
included in the result set. This means counting the number of resulting rows
will not correspond to the number of unique dependent packages.
Additionally a package may have required gopkg.in/yaml.v3 version v3.0.1 at some
time in the past, but has since removed or updated its dependency requirement.
To select unique packages that currently depend on gopkg.in/yaml.v3 version
v3.0.1 we can filter the result set to include only the versions that are the
newest release of their package.
SELECT
Dependent.System,
Dependent.Name,
Dependent.Version
FROM
`bigquery-public-data.deps_dev_v1.DependentsLatest`
WHERE
System = 'GO'
AND Name = 'gopkg.in/yaml.v3'
AND Version = 'v3.0.1'
AND DependentIsHighestReleaseWithResolution;
This query can easily be adjusted to find all packages whose highest release
depends on any version of gopkg.in/yaml.v3.
SELECT DISTINCT
Dependent.System,
Dependent.Name
FROM
`bigquery-public-data.deps_dev_v1.DependentsLatest`
WHERE
System = 'GO'
AND Name = 'gopkg.in/yaml.v3'
AND DependentIsHighestReleaseWithResolution;
Direct or indirect dependents only
The result sets returned by all the queries provided so far include
both direct and indirect dependents of gopkg.in/yaml.v3. To find the
packages that import gopkg.in/yaml.v3 directly we can make use of the
MinimumDepth column of the Dependents table.
This column contains the minimum depth of the dependency in the corresponding
dependency graph. It is a minimum depth because there may be multiple paths to a
dependency.
A depth of 1 indicates direct dependency. A depth greater than 1 indicates an
indirect dependency.
The following query selects all unique packages that currently depend on any
version of gopkg.in/yaml.v3 directly.
SELECT DISTINCT
Dependent.System,
Dependent.Name
FROM
`bigquery-public-data.deps_dev_v1.DependentsLatest`
WHERE
System = 'GO'
AND Name = 'gopkg.in/yaml.v3'
AND DependentIsHighestReleaseWithResolution
AND MinimumDepth = 1;
Limitations of these queries
There are some caveats to the queries provided in this post that are worth
consideration.
The data does not include closed source dependents
The dataset only includes software that has been published on one of the
dependency management systems tracked by deps.dev. Consequently no queries can
contain closed source code that depends on a given package.
A package may see wide spread use in proprietary applications, but this
popularity will not necessarily be reflected in the number of publicly available
dependents.
Context matters
It is common practice across most dependency management systems to allow
libraries to specify a range of compatible versions for each of their
dependencies. As a result most OSS packages can have their dependency
requirements met by many different dependency graphs.
The context in which a library is used can determine the exact dependencies that
will be installed.
To compute the dependency and dependent relation in the deps.dev
dataset a single dependency graph is resolved for each version of
every package tracked by deps.dev. The dependencies we have should be
similar to those obtained when installing the dependencies of a
package with native tooling in a clean workspace on a Linux
machine. This is also true of API calls that return dependencies like
GetDependencies.
It is important to note that different dependency resolutions are possible.
Closing thoughts
Securing the software supply chain is essential, and understanding the complex
interrelationships of OSS software is a key part of that.
This post has shown some of the ways the deps.dev dataset can be used
to achieve this goal. We are excited to see what you can do with this
dataset.
Today we’re launching support for NuGet, the .NET package manager. We have 350k
NuGet packages and 5.6 million package versions available through our
API, website and
BigQuery dataset.
Deps.dev already supports npm, Go, Maven, PyPI, Cargo and we’re excited to add
support for NuGet as another major open source ecosystem. As software supply
chain attacks continue to increase in number and in complexity, it’s becoming
more important than ever to understand the software that we depend on. We hope
that more developers will be able to gain insight into their dependencies
through our NuGet support.
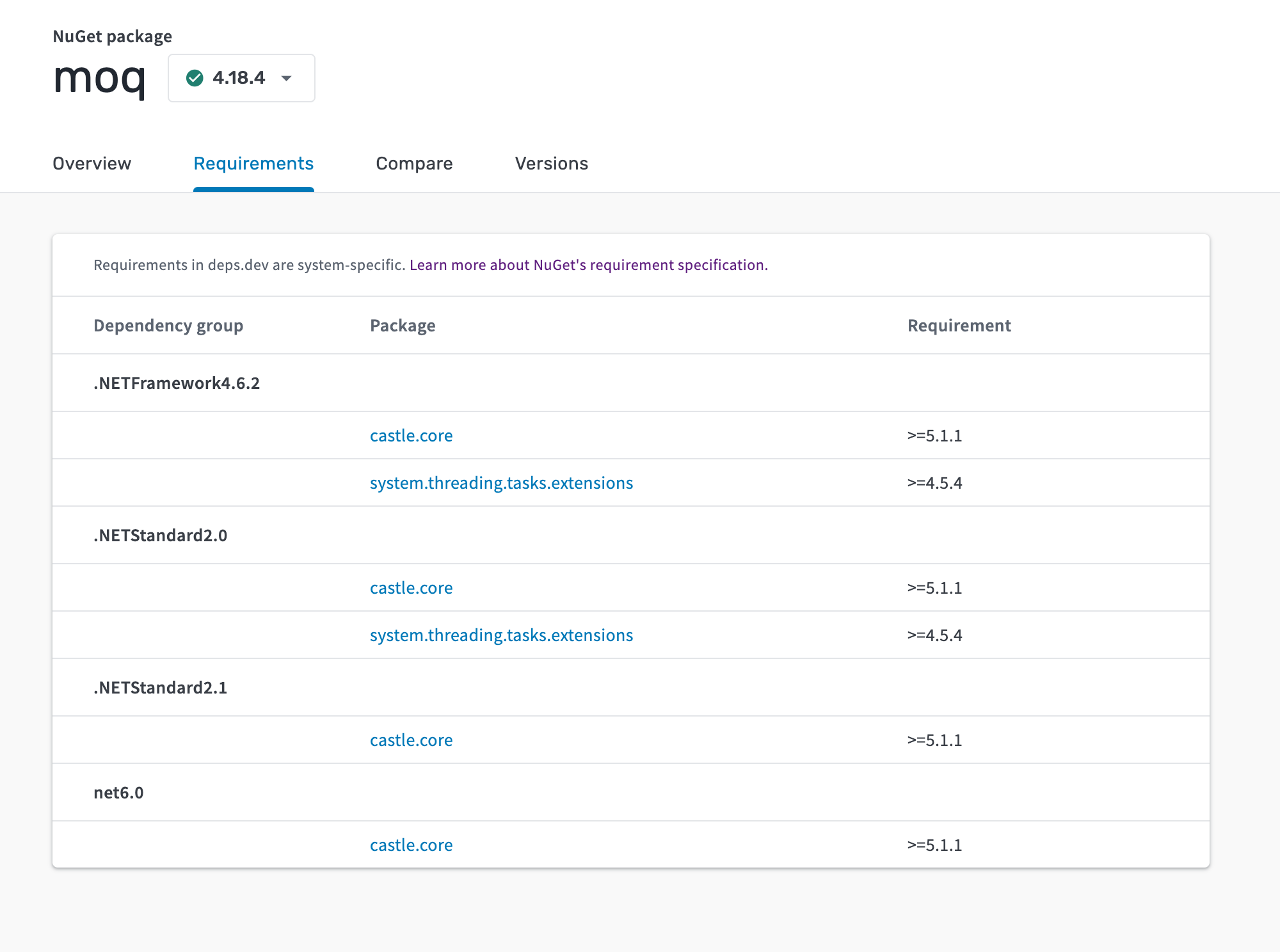
Introducing Requirements
NuGet is our first supported ecosystem to feature dependency requirement data
instead of dependency graphs.
Requirements are the link between a package and its dependency graph. In NuGet,
requirements are specified by including a
dependencies tag
in the .nuspec or a
package reference
tag in the .csproj file.
<dependencies>
<!-- Require a version of Castle.Core between 4.0.0 and 5.1.0,
including 4.0.0 but excluding 5.1.0. -->
<dependency id="Castle.Core" version="[4.0.0, 5.1.0)" />
<!-- Require a version of Serilog that's >=2.12.0, preferring lower versions. -->
<dependency id="Serilog" version="2.12.0" />
</dependencies>
Example of a dependencies tag in a .nuspec file. Note that 'dependency' in
NuGet means 'requirement'. In deps.dev we make a distinction between a
dependency (a resolved requirement) and a requirement (a package constraint).
These requirements are read by the NuGet resolver and resolved into a
dependency graph. For example, the requirements above would resolve into the
following graph.
The resolved dependency graph for the .nuspec snippet above. My.Package/1.0.0 depends on Castle.Core/5.0.0 and Serilog/2.12.0, and transitively depends on four more System packages.
In the case of NuGet, it’s possible to specify requirements for specific target frameworks.
An example .nuspec snippet showing multiple dependency groups for
different target frameworks.
Requirements are usually interpreted within the rules of semantic versioning
(semver), but the semver standard only covers version numbers. It doesn’t go
into how requirements should be specified. So for each ecosystem there are
different requirement operators and rules for requirement interpretation. For
NuGet, there is official documentation on
requirement rules
and
resolution.
You can find a brief comparison of requirement specification rules across
ecosystems in our glossary.
Since requirements determine the allowable dependency graphs, some interesting
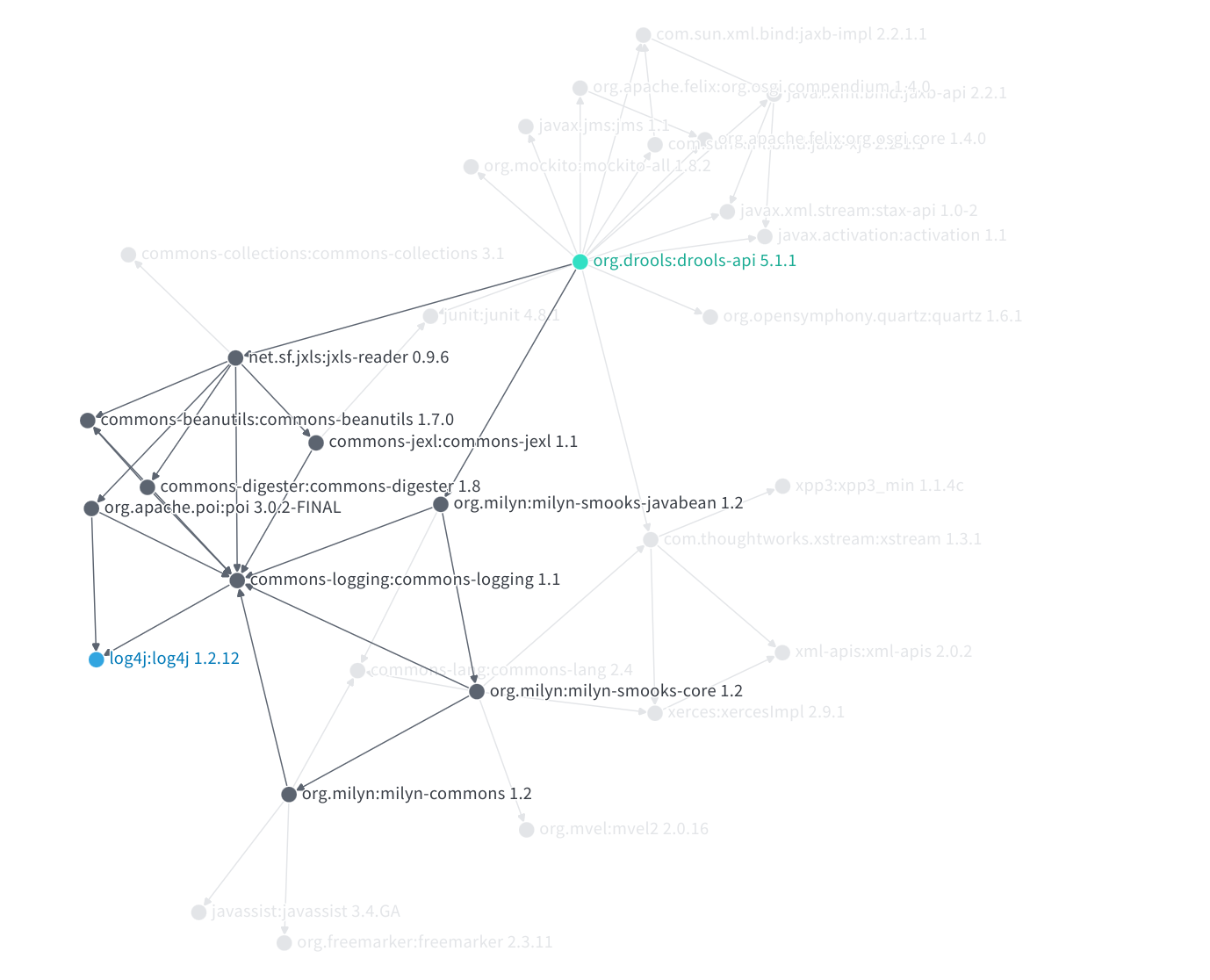
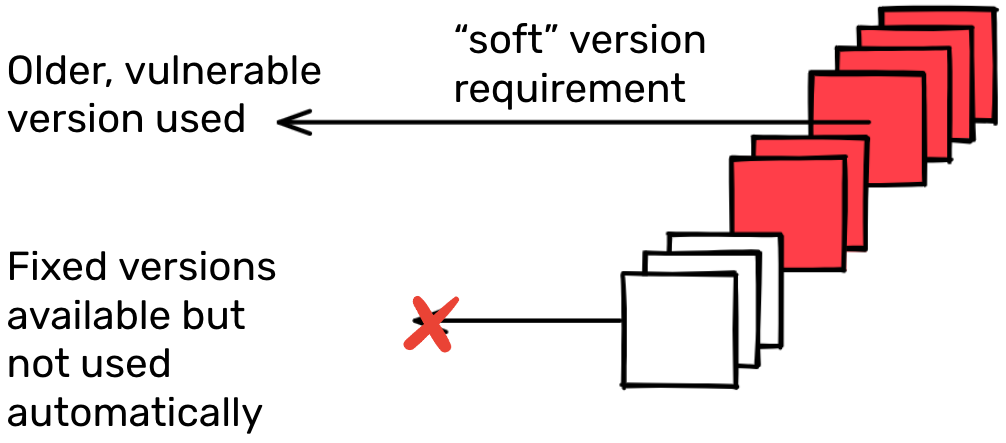
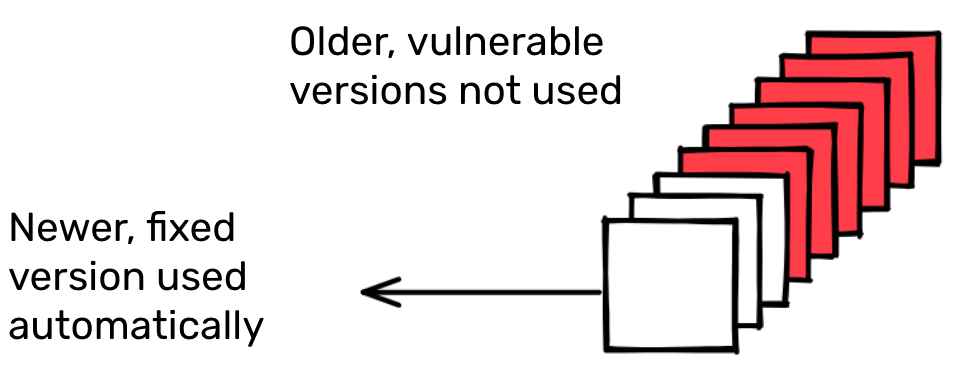
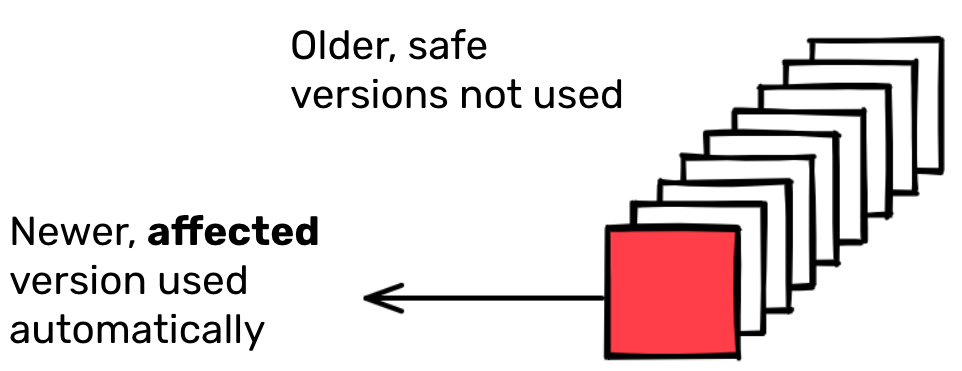
analysis can be done on how and why dependency graphs change. For example, it
might be interesting to know whether a package would automatically pick a
recently released version of a package for its dependency graph. Requirements
can be used to determine this. Knowing whether a package would automatically
pick up a new version of an existing dependency is particularly useful when we
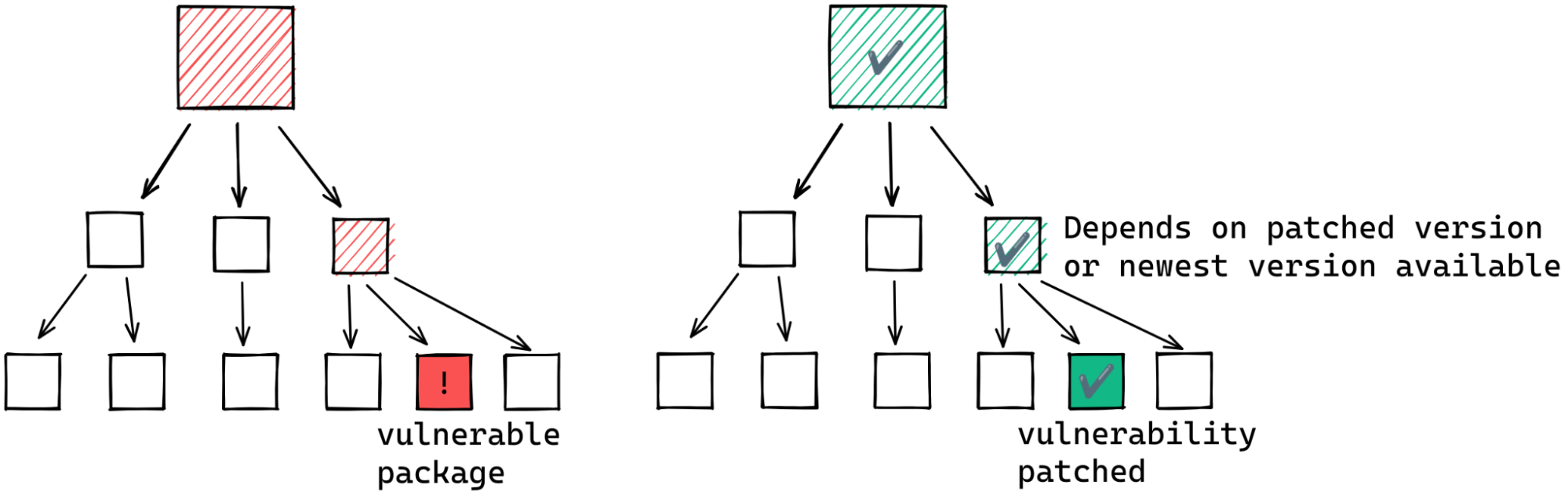
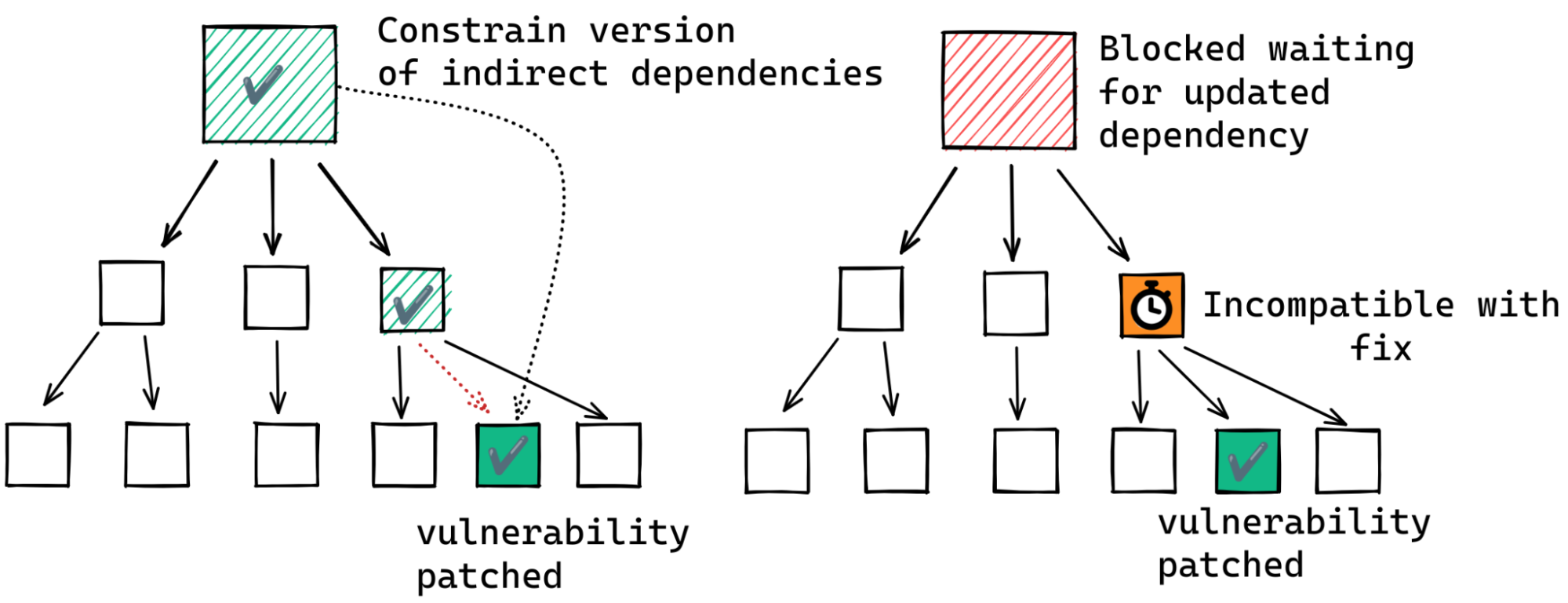
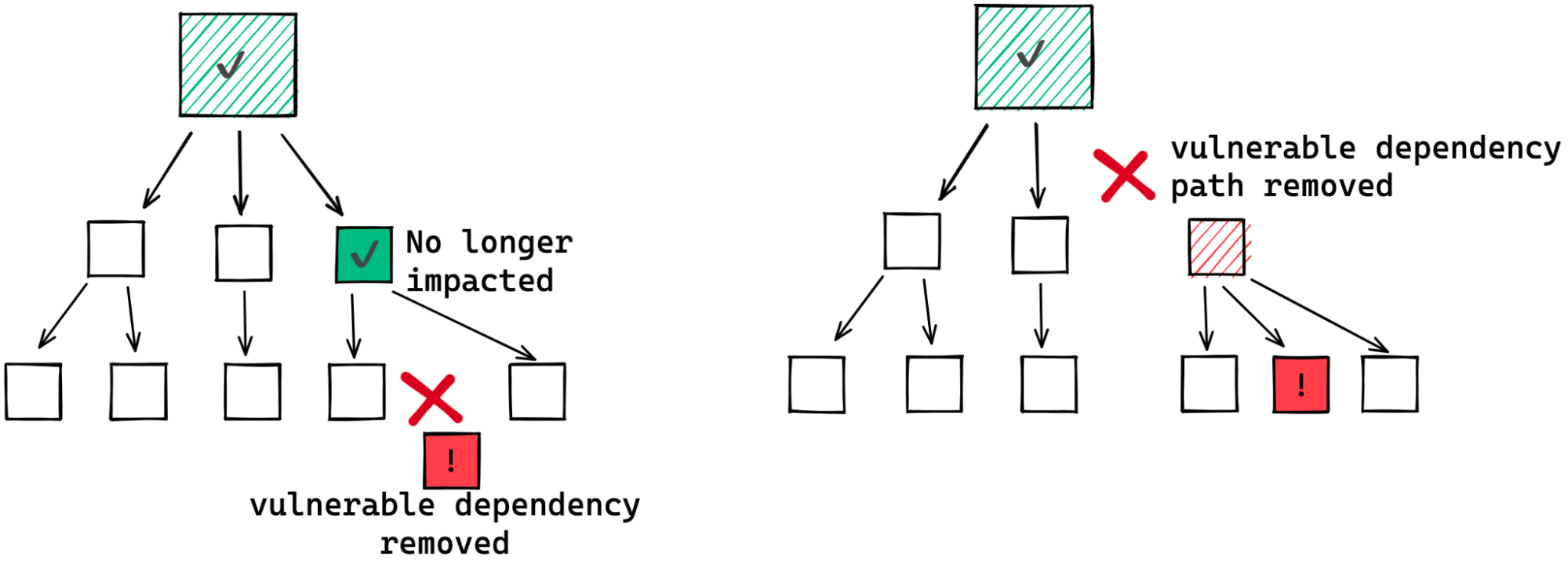
think about remediating vulnerabilities introduced by transitive dependencies.
Where does the data come from?
The main source of data is the .nuspec file of the package itself, which is
available from the NuGet
PackageContent API.
We also use the
NuGet Search API
and
Catalog API
for version metadata fields not available in the .nuspec file.
We’d like to thank the NuGet team for helping us develop support for NuGet on
deps.dev. Each time we develop support for a new ecosystem we discover
interesting differences across ecosystems that require us to expand our backend
data model and infrastructure. It was great having the official maintainers
lend a hand in helping us understand the NuGet ecosystem.
Hashes: You can use the
Query API endpoint to query
for the name of a mystery NuGet package by using its hash.
Advisories: You can check whether a NuGet package version is directly
affected by an advisory, and if so, whether there is an unaffected version
you could use.
We’re hoping to improve our license support for NuGet, as NuGet allows multiple
ways to specify a package’s license.
We’re also planning on adding requirement information for other ecosystems.
We’d love to hear what you think about our NuGet support. As mentioned earlier,
NuGet is our first ecosystem to feature requirements, so we’re interested in
hearing about your experiences (both good and bad) working with this new kind
of data. Get in touch via email at
depsdev@google.com or file an
issue to our GitHub repository.
Not knowing where your software dependencies come from leaves your codebase
vulnerable to breaches, exploits and supply chain attacks. Just since the
beginning of 2023 we’ve seen
manyexamples
of actors attempting to
injectmaliciouspackages
into open source consumers supply chains. With SLSA
provenance attestations, users can verify an artifact’s build integrity to
ensure that malicious parties have not created, tampered with or replaced the
code they’re running.
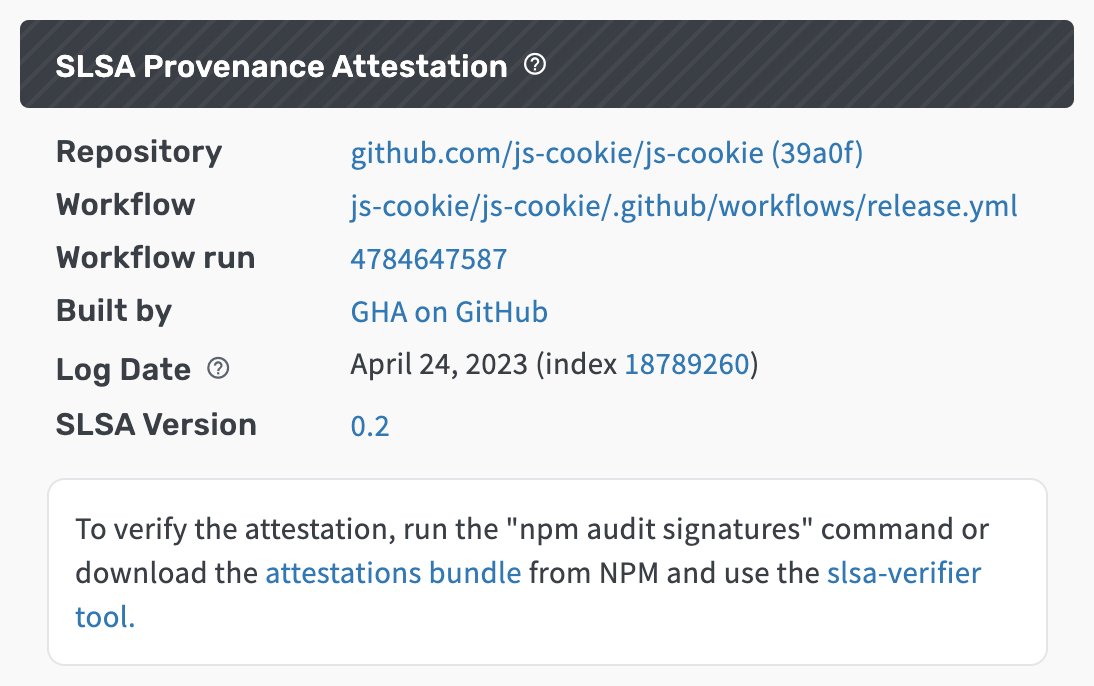
We are excited to announce that deps.dev now shows SLSA provenance information
for npm packages to provide more information and improve trust for package
consumers. You can view the provenance information for supported npm packages
on deps.dev — for example,
deps.dev/npm/js-cookie.
Screenshot of deps.dev provenance UI for the npm js-cookie package
SLSA provenance is metadata about how a package was built and strongly links an
open source package to the build system and source code used to create it. It
is part of the SLSA framework for improving supply chain security. In the
provenance attestation you can find:
the repository and commit at which the version was built
details about the workflow used to create the version
how the version was built
the date the attestation was integrated into the
rekor transparency log.
npm recently announced the public beta for their integration with the
Sigstore project. This allows package owners to
upload cryptographically verifiable SLSA provenance attestations along with
their packages. In the future, integrations with the npm CLI tool will
automatically verify attestations on install, making working in npm more secure
by default. (However, it’s important to note that not all npm packages will
have these attestations and older versions will not automatically be
republished. Further information is available in npm’s announcement).
It’s great to see npm working to make the open source ecosystem more secure and
we hope to see other package managers follow suit! For more information about
SLSA visit the SLSA homepage. Instructions are available
for npm package maintainers who want to add SLSA provenance
information to their packages.
Today, we are excited to announce the deps.dev
API, which provides free access to the
deps.dev dataset of security metadata, including dependencies, licenses,
advisories, and other critical health and security signals for more than 50
million open source package versions.
Software supply chain attacks are increasingly common and harmful, with high
profile incidents such as
Log4Shell,
Codecov, and the recent 3CX
hack.
The overwhelming complexity of the software ecosystem causes trouble for even
the most diligent and well-resourced developers.
We hope the deps.dev API will help the community make sense of complex
dependency data that allows them to respond to—or even prevent—these types
of attacks. By integrating this data into tools, workflows, and analyses,
developers can more easily understand the risks in their software supply
chains.
The power of dependency data
As part of Google’s ongoing efforts to improve open source
security,
the Open Source Insights team has built a reliable view of software metadata
across 5 packaging ecosystems. The deps.dev data set is continuously updated
from a range of sources: package registries, the Open Source Vulnerability
database, code hosts such as GitHub and GitLab, and the
software artifacts themselves. This includes 5 million packages, more than 50
million versions, from the Go, Maven, PyPI, npm, and Cargo ecosystems—and
you’d better believe we’re counting them!
We collect and aggregate this data and derive transitive dependency graphs,
advisory impact reports, OpenSSF Security
Scorecard information, and more. Where the
deps.dev website allows human exploration and examination,
and the BigQuery dataset supports
large-scale bulk data analysis, this new API enables programmatic, real-time
access to the corpus for integration into tools, workflows, and analyses.
The API is used by a number of teams internally at Google to support the
security of our own products. One of the first publicly visible uses is the
GUAC
integration,
which uses the deps.dev data to enrich
SBOMs.
We have more exciting integrations in the works, but we’re most excited to see
what the greater open source community builds!
We see the API as being useful for tool builders, researchers, and tinkerers
who want to answer questions like:
What versions are available for this package?
What are the licenses that cover this version of a package—or all the
packages in my codebase?
How many dependencies does this package have? What are they?
Does the latest version of this package include changes to dependencies or
licenses?
What versions of what packages correspond to this file?
Taken together, this information can help answer the most important overarching
question: how much risk would this dependency add to my project?
The API can help surface critical security information where and when
developers can act. This data can be integrated into:
IDE Plugins, to make dependency and security information immediately
available.
CI/CD integrations to prevent rolling out code with vulnerability or license
problems).
Build tools and policy engine integrations to help ensure compliance.
Post-release analysis tools to detect newly discovered vulnerabilities in
your codebase.
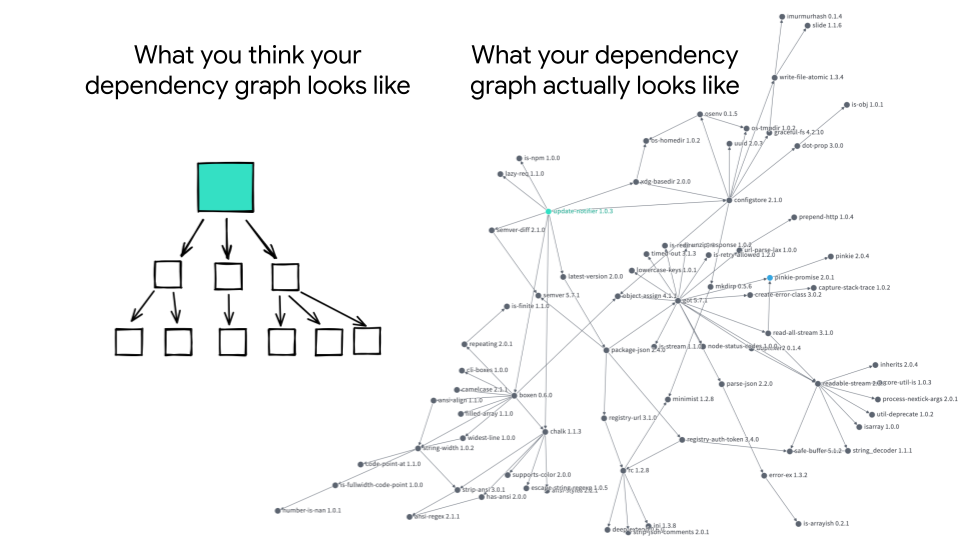
Tools to improve inventory management and mystery file identification.
Visualizations to help you discover what your dependency graph actually
looks like:
What you think your dependency graph looks like vs what your dependency graph actually looks like
Unique features
The API has a couple of great features that aren’t available through the
deps.dev website.
Hash queries
A unique feature of the API is hash queries: you can look up the hash of a
file’s contents and find all the package versions that contain that file. This
can help figure out what version of which package you have even absent other
build metadata, which is useful in areas such as SBOMs, container analysis,
incident response, and forensics.
Real dependency graphs
The deps.dev dependency data is not just what a package declares (its
manifests, lock files, etc.), but rather a full dependency graph computed using
the same algorithms as the packaging tools (Maven, npm, Pip, Go, Cargo). This
gives a real set of dependencies similar to what you would get by actually
installing the package, which is useful when a package changes but the
developer doesn’t update the lock file. With the deps.dev API, tools can
assess, monitor, or visualize expected (or unexpected!) dependencies.
API in action
For a demonstration of how the API can help software supply chain security
efforts, consider the questions it could answer in a situation like the
Log4Shell discovery:
Am I affected? - A CI/CD integration powered by the free API would
automatically detect that a new, critical vulnerability is affecting your
codebase, and alert you to act.
Where? - A dependency visualization tool pulling from the deps.dev API
transitive dependency graphs would help you identify whether you can update
one of your direct dependencies to fix the issue. If you were blocked, the
tool would point you at the package(s) that are yet to be patched, so you
could contribute a PR and help unblock yourself further up the tree.
Where else? - You could query the API with hashes of vendored JAR files
to check if vulnerable log4j versions were unexpectedly hiding therein.
How much of the ecosystem is impacted? - Researchers, package managers,
and other interested observers could use the API to understand how their
ecosystem has been affected, as we did in this blog post about Log4Shell’s
impact.
Getting started
The API service is globally replicated and highly available, meaning that you
and your tools can depend on it being there when you need it.
It’s also free and immediately available—no need to register for an API key.
It’s just a simple, unauthenticated HTTPS API that returns JSON objects:
# List the advisories affecting log4j 1.2.17
$ curl https://api.deps.dev/v3alpha/systems/maven/packages/log4j%3Alog4j/versions/1.2.17 \
| jq '.advisoryKeys[].id'
"GHSA-2qrg-x229-3v8q"
"GHSA-65fg-84f6-3jq3"
"GHSA-f7vh-qwp3-x37m"
"GHSA-fp5r-v3w9-4333"
"GHSA-w9p3-5cr8-m3jj"
A single API call to list all the GHSA advisories affecting a specific version of log4j
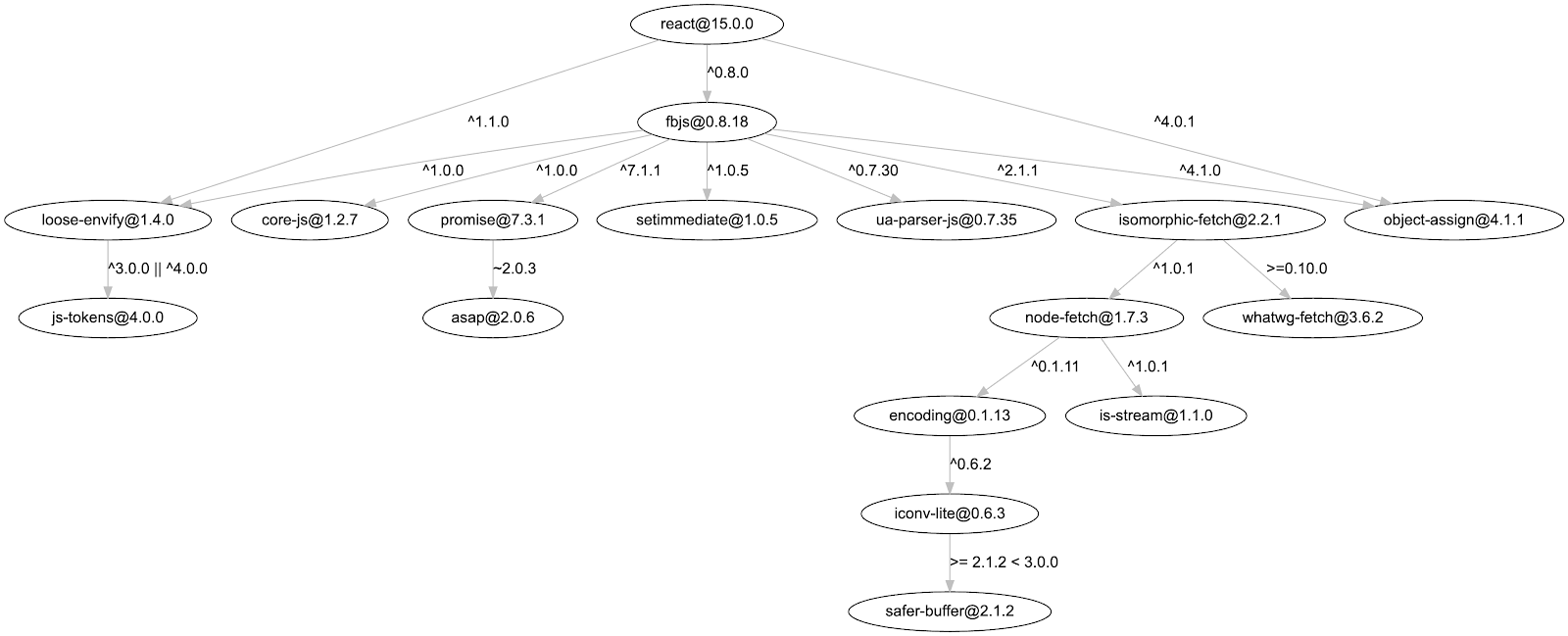
Dependency graph for react 15.0.0, fetched from the deps.dev API and rendered using GraphViz
Securing supply chains
Software supply chain security is hard, but it’s in all our interests to make
it easier. Every day, Google works hard to create a safer internet, and we’re
proud to be releasing this API to help do just that, and make this data
universally accessible and useful to everyone.
We look forward to seeing what you might do with the API, and would appreciate
your feedback. (What works? What doesn’t? What makes it better?) You can reach
us at depsdev@google.com, or by filing an issue on
our GitHub repo.
James Wetter and Nicky Ringland, Open Source Insights Team
How can a user of open source software (OSS) assess their risk of exposure to a
future vulnerability when taking on a new dependency?
Vulnerabilities will always find their way into software, and in an ideal world
those vulnerabilities will be fixed in a reasonable amount of time. This is a
critical factor for building trust between OSS maintainers and the users of
their software.
This blog post looks at the events around the remediation of a vulnerability,
and a few ways that trust can be established between maintainers and users of
OSS. In particular we examine how often OSS packages remediate known
vulnerabilities and if their users were left exposed after the vulnerability was
publicly disclosed.
An ideal remediation
next-auth is an npm package that provides
tools to help implement authentication for the web development framework
Next.js. next-auth is popular, with almost 200,000
weekly downloads according to npm. Recently an
advisory
was published detailing a critical vulnerability in the next-auth package. Due
to this vulnerability, an attacker could potentially gain access to another
user’s account.
Fortunately for the users of next-auth, the reporter of the vulnerability and
package maintainer practiced coordinated vulnerability
disclosure. As
a result a fixed version of next-auth was already available when this advisory
was published. Both versions 4.10.3 and 3.29.10 include a patch remediating the
vulnerability.
The advisory itself contains a brief timeline of key events. The vulnerability
was discovered by Socket, and privately disclosed to the
maintainers of next-auth on the 26th of July. The maintainers acknowledged the
private disclosure within 1 hour, and released remediating versions on the 1st
of August. Two days later, an advisory disclosing the vulnerability was
published. The time between private disclosure and the release of a fix, the
time to remediation, was approximately 5 working days.
The events surrounding a coordinated vulnerability disclosure.
This situation is ideal. Both the private disclosure of the vulnerability and
rapid response of the package maintainers meant that the two most recent major
versions both had patched versions available for users before the publication of
the advisory.
By the time the advisory was published, most users of the next-auth package
would be able to move to a patched version immediately with little effort. This
virtually eliminated the post-advisory exposure time for the many users of the
package.
What can go wrong?
Things don’t always work out as well as this, though. There are a few ways in
which the process could go awry such as the discovery of a zero-day exploit, or
a vulnerability in an unmaintained package.
A zero-day exploit
The events surrounding a hypothetical zero day exploit.
A zero-day exploit is when a vulnerability is being actively exploited by the
time the package maintainers become aware of the issue. In these situations it
may be better to publish an advisory before the maintainers have developed a
patch in order to raise awareness as quickly as possible. This was the case for
the well publicized remote code injection
vulnerability in the
popular log4j
library.
In this scenario, it is not reasonable to expect the maintainers to remediate
the vulnerability before the advisory is published - increased awareness is a
higher priority. And as a result the users of the package will be exposed to a
publicly known vulnerability until a remediation is made available, or they
remove their dependency on the affected package.
An unmaintained package
The events surrounding a failed coordinated vulnerability disclosure for a hypothetical unmaintained package.
When a vulnerability is discovered in a package that is no longer maintained
there will be no response to private disclosure, leaving the reporter no choice
but for the reporter to publish an advisory without a fix available.
An example of this situation is the once popular npm package
parsejson. Its most recent release has an
unremedied, high severity
vulnerability that was
publicly disclosed in 2018. But the package hasn’t seen a new release since 2016.
Its GitHub repository has been archived
and clearly states that it is no longer maintained. Worryingly, the package is
still widely used: npm reports that the package still gets almost 250,000 weekly
downloads.
It’s clear that users of OSS should not introduce new dependencies on an
unmaintained package like parsejson. Existing users should remove such
dependencies from their libraries and applications as quickly as they can. But
it can be hard for a developer to know when one of their dependencies is no
longer maintained or less actively maintained. Signals to help identify changes
in the maintenance status are critical.
What usually happens after an advisory?
For our discussion here, we consider a package to have remediated an advisory
when it has a release that
is not affected by the advisory, and
has a greater version number than all affected releases.
The semantics of versions and release differ between systems. For example PyPI
uses pep440, while npm uses semantic
versioning.
This definition of remediation means that if the greatest major version of a
package has a fix available, the package is considered to have remediated the
vulnerability even if lesser major versions remain affected. There is more to be
said about packages that have multiple major versions, each of which may be
fixed independently, but we will leave a discussion of the nuance of
vulnerabilities and multiple major versions for another time.
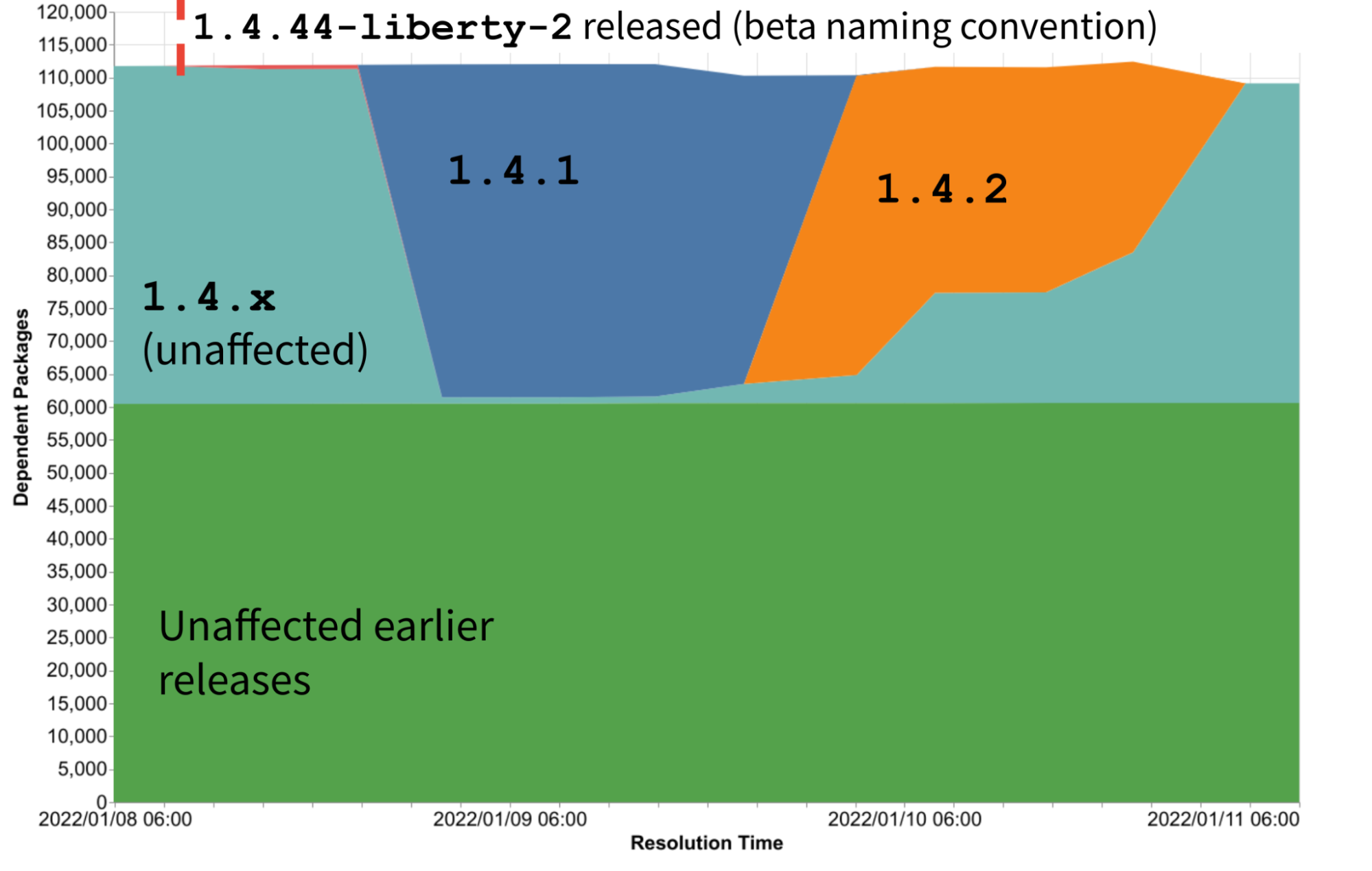
Clearance rates
First let’s take a look at how many known vulnerabilities are remediated.
Across every package management system supported by deps.dev, we see that most
package maintainers do respond to vulnerability advisories in their packages.
There is considerable variation between ecosystems. The lower clearance rate
seen in the Cargo ecosystem is expected. Within that ecosystem, there is a
practice of publishing an advisory that a package is unmaintained, such as this
advisory and this
advisory. Such
advisories are not expected to be remediated, but publishing them helps raise
awareness of the package’s unmaintained state amongst its users.
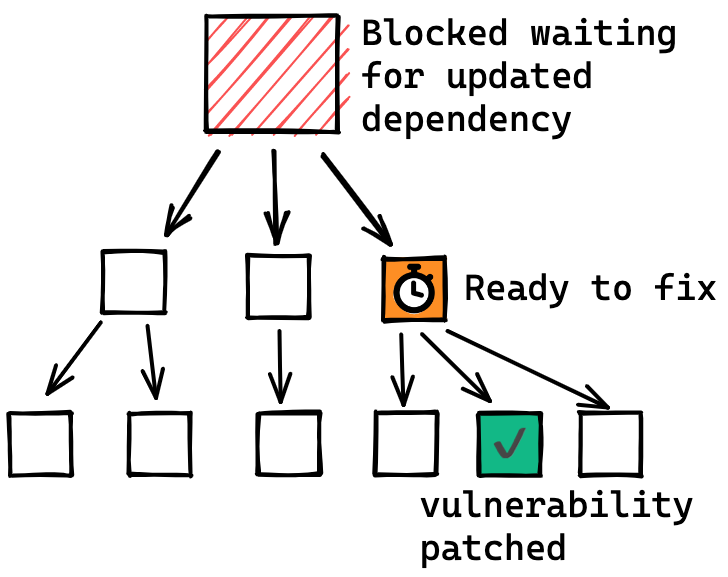
Taking a closer look at individual packages, the clearance rate of
vulnerabilities gives an indication of the health of the package, and consequent
risk of using the package. Some packages have a very high number of known
vulnerabilities in older versions, but all of the vulnerabilities have been
remediated. For example
These packages are healthy and well maintained, and their high clearance rates
are a good indication of that.
Post-advisory exposure time
Now let’s consider how long users are exposed to a known vulnerability without a
fix. That is, the interval between the publication of an advisory and the
publication of a release to remediate it. We call this the post-advisory
exposure time.
The PyPI, Cargo and npm packaging systems expose the publication times for each
version. Using this data we can examine the post-advisory exposure time.
The post-advisory exposure time across the PyPI, Cargo and npm ecosystems for all the vulnerabilities in the deps.dev dataset.
At a glance these graphs paint a positive picture. Each ecosystem appears
healthy, with the majority of vulnerabilities disclosed in an advisory being
remediated very quickly. This demonstrates that security is a priority for most
maintainers.
But it should be noted that vulnerabilities where coordinated disclosure was
successful will have zero post-advisory exposure time (or even negative
time!). In npm and PyPI almost 60% of the vulnerabilities in our database were
remediated before the publication of the corresponding advisory. Cargo has a
much lower percentage, around 16%; more on that shortly.
Let’s direct our attention to cases that did not see a coordinated vulnerability
disclosure. The following histograms show the post-advisory exposure time,
excluding successfully coordinated disclosures.
The post-advisory exposure time across the PyPI, Cargo and npm ecosystems for the vulnerabilities in the deps.dev dataset that didn't have a coordinated disclosure.
In all three systems, many vulnerabilities are remediated within 30 days of
advisory publication. This includes many zero-day exploits, such as
log4shell, that were fixed as quickly
as possible, even without the more ideal option of a coordinated vulnerability
disclosure.
In the case of Cargo, the number resolved in the first 30 days is a staggering
70% of all vulnerabilities remediated after advisory publication. This is
because many maintainers choose to release the remediation on the same day the
advisory is published, resulting in non-zero but very brief post-advisory
exposure time.
The long tail of vulnerabilities with significant post-advisory exposure time is
a valuable signal on the health of the corresponding packages. For developers
taking on new dependencies, knowing that they will not be left exposed for long
periods of time is critical to their security posture. For existing users of a
dependency, being aware of changes to future remediation likelihood of potential
vulnerabilities is equally important.
Currently it is hard to know how a given package has previously performed
according to this metric. Ideally this information would be easily accessible,
allowing potential and existing users to make informed decisions about their
dependencies.
Mean time to remediation
The number of known vulnerabilities that a package maintainer has remediated in
the past can be used to help build trust between maintainers and users of
OSS. Additionally, the length of time users of a package were left exposed to
known, unremedied vulnerabilities in the past can provide a more detailed
characterization of a package maintainer’s response.
In addition to these signals, Mean Time to Remediation (MTTR) has been proposed
as a useful indicator of the quality of a package’s maintenance.
However, the available data about advisories rarely contains timestamps for
critical events in the remediation process. For example, most advisory
databases, including GitHub Advisories and OSV, do not provide a timestamp field
for the private disclosure of the vulnerability or the maintainers
acknowledgement. And while some advisory write-ups do include an event timeline,
these are quite rare.
These missing timestamps make it impossible to compute the time that elapsed
between a maintainer being notified of a vulnerability and the release of a
remediation, relegating MTTR to a, for now, still hypothetical metric to
compute.
Conclusion
Vulnerabilities are an inevitable part of software development. The code reuse
and efficiency gains made possible by OSS broadens the potential impact of
vulnerabilities.
But cooperation between parties that discover vulnerabilities and package
maintainers reduces the time that users are left exposed to publicly known
vulnerabilities. Thanks to the hard work of OSS maintainers, there is no
post-advisory exposure for the majority of vulnerabilities in our advisory
database.
Developers should still prepare for less ideal outcomes. Every dependency they
introduce increases the risk of exposure to future vulnerabilities. The
clearance rate and post-advisory exposure time for past advisories can provide
users of OSS assurance about the quality of maintenance their dependencies
receive. While past performance may not always predict future behavior, it can
be used as a valuable signal to help make informed decisions.
Open source software powers the world. Open source libraries allow
developers to build things faster, organizations to be more nimble,
and all of us to be more productive.
But dependencies bring complexity. Popular open source packages are
often used directly or indirectly by a significant portion of the
packages within an ecosystem. As a result, a vulnerability in a
popular package can have a massive impact across an entire ecosystem.
Different software ecosystems have different conventions for
specifying dependency requirements and different algorithms for
resolving them. We will take a look at a couple of large profile
incidents that discuss some of these differences.
The amplification of vulnerability impact
To measure the potential impact of a vulnerability, we can look at how
many dependents it has. That is, how many other packages that use a
specific version that is affected by a vulnerability. We can get a
view of an ecosystem by looking at all package versions that are
affected - either directly or indirectly - by a vulnerability.
First off: packages that are directly affected. At the time of
writing, across all the packaging systems supported by deps.dev, over
200 thousand package versions (0.4%) are directly named as vulnerable
by a known advisory.
In contrast, almost 15 million package versions (33%) are affected
only indirectly, by having an affected package in their dependency
graph. That’s two orders of magnitude difference!
Dependencies magnify the impact of vulnerabilities.
That underpins just how hard it is to fix a vulnerability in an
ecosystem. When a package explicitly named by an advisory publishes a
fix for the issue, the story is far from over. Many users of the
packaging ecosystem will still be at risk, because they depend on
vulnerable versions of the package deep within their dependency
graphs. Fixing the directly affected package is often only the tip of
the iceberg.
Addressing vulnerabilities in your dependencies
There are several ways an application maintainer could mitigate a
vulnerability affecting one of their dependencies. Let’s be kind to
our hypothetical maintainer and consider a simple dependency tree with
two layers of dependencies.
An application may have direct and indirect dependencies.
If this maintainer is lucky, they depend on the affected package
directly. That means as soon as the affected package publishes a fixed
version they can update their project or application to depend on the
fixed version.
A vulnerability in a direct dependency.
But if the vulnerable package is among their indirect dependencies the
situation could be much more complex.
In the best case scenario, the intermediate packages already depend on
the patched version.
A vulnerability in an indirect dependency.
If this is not the case, our hypothetical maintainer may still have a
course of action. To update to the fixed version of the indirect
dependency the maintainer may be able to specify the fixed version as
a minimum for the entire dependency graph. For this to work, however,
the fixed version of the affected package and its direct dependents
must be compatible. If not, the maintainer may have to wait for a new
release of the intermediate dependent.
An indirect dependency can often have its version pinned, but incompatibile intermediate dependencies may be a problem.
Another alternative is to remove the dependency on the affected
package. But this often involves considerable effort; you would never
have added a dependency without good reason, right?
A vulnerability in a dependency can be mitigated by removing that dependency.
In practice, dependency trees are rarely so simple and clean. Usually
they are complex, interconnected graphs. Just take a look at the
dependency graphs for popular frameworks and tools like
express or
kubernetes.
The dependency graph of a version of express.
These complex graphs can make remediating a vulnerability far more
difficult than the simple examples given above. There may be many
paths through which a fix must propagate before it gets to you. Or, in
order to remove a dependency, you might need to remove a significant
portion of your dependency graph.
For example, consider the many
paths
by which one package depends on a vulnerable version of log4j:
Various paths from through a dependency graph to a vulnerable version of log4j.
With this in mind, perhaps you can imagine why it often takes a long
time for a patched version of a popular package to roll out to the
ecosystem.
log4shell in the Maven Central ecosystem
On December 9th last year, over 17,000 of the Java packages available
from Maven central were impacted by the log4j vulnerabilities, known
as log4shell, resulting in widespread fallout across the software
industry. The vulnerabilities allowed an attacker to perform remote
code execution by exploiting the insecure JNDI lookups feature exposed
by the logging library log4j. This exploitable feature was present in
multiple versions, and was enabled by default in many versions of the
library. We wrote about this incident shortly after it occurred in a
previous blog.
A new version of log4j with the vulnerability patched (albeit with few
false starts due to incomplete fixes) was available almost
immediately. So once that patched version was published had the
ecosystem freed itself of log4shell? Unfortunately not. Part of what
makes fixing log4shell hard is Java’s conventions on how dependency
requirements are specified, and Maven’s dependency resolution
algorithm itself.
In the Java ecosystem, it’s common practice to specify “soft” version
requirements. That is, the dependent package specifies a single
version for each dependency, which is usually the version that ends up
being used. (The dependency resolution algorithm may choose a
different version under certain rare conditions – for example, a
different version already in the graph). While it is possible to
specify ranges of suitable versions, this is unusual. More than 99% of
dependency requirements in the Maven Central ecosystem are specified
using soft requirements.
Here’s where Maven’s dependency resolution algorithm comes in. Since
almost all the time, a specific version has been specified, that’s
almost always the version that the dependency resolution will pick. So
if a newer version with that important new bug fix is released, it
won’t be included automatically. It usually requires explicit action
by the maintainer to update the dependency requirements to a patched
version.
As a result of the pervasive use of 'soft' dependency requirements old, vulnerable versions of a package may continue to be depended on long after the release of a patched version.
In this case, consumers of any one of the 17,000 odd packages affected
by the log4j vulnerabilities would likely still depend on an affected
version of log4j, even after the first fix was published. Ideally the
maintainers of around 4,000 packages that directly depend on log4j
would promptly release a new version of their package that explicitly
requires a fixed version of log4j. Then the maintainers of packages
that depend on those packages can update their version requirements,
and then maintainers of those packages, and so on. There are methods
to pin the version of indirect dependencies accelerating this process,
but many consumers rely on the default behavior of their tools.
It’s been over six months since the log4 advisory was disclosed. How
well has the underlying fix to log4shell propagated throughout the
ecosystem? A little less than a week after the disclosure around 13%
of affected packages had remediated the issue by releasing a new
version. 10 days after disclosure this number had risen to around
25%. Now a few months after that we see around 40% of the affected
packages have remediated the problem. Considering how widespread the
problem was, and the complexity of the dependencies between packages,
this is amazing progress, but there’s clearly a lot more to go.
Default versions: new or old?
Package managers differ in which versions they choose to install by
default. For example, systems like Maven or Go err on the side of
choosing earlier matching versions, while npm and Pip tend to choose
later versions. This design choice can have a big impact on how a fix
rolls out or, conversely, how quickly an exploit can propagate.
Choosing the earlier versions has the benefit of stability; dependency
graphs remain stable whether you install today or tomorrow, even if
new versions are released. The downside is that the consumer must be
conscientious in updating their dependencies when security issues
arise.
Choosing the later versions has the benefit of currency; you get the
latest fixes automatically just by reinstalling. The downside here is
that your dependencies can change underfoot, sometimes in dramatic and
unexpected ways.
With this in mind, if log4shell had occurred in the npm or PyPI
ecosystems the story would have been quite different. In these
ecosystems, packages typically ask for the most recent compatible
versions of their dependencies.
The conventions of npm mean fixes can propagate throughout the ecosystem automatically.
Looking at the dependency requirements across all versions of all
packages in npm we find around three quarters use the caret (^) or
tilde (~) allowing a new patch or minor version of the dependency to
be automatically selected when available. When adhering to semantic
versioning, this means that many users will use
the newest release with a compatible API by default.
This practice would likely have been a substantial benefit in
remediating a log4shell-like event, where a vulnerability is
discovered in widely used versions of a popular package.
But as we shall see, sometimes we really, really don’t want to use the
latest version.
The case of colors
In early January 2022, the developer of the popular npm packages
colors and faker intentionally published several releases containing
breaking changes. These were picked up rapidly due to the npm
resolution algorithm preferencing recent releases, and the norm in
javascript of using dependency requirements that allow the use of new
compatible versions automatically.
The conventions of npm mean new malicious code can propagate throughout the ecosystem rapidly.
At the time of the incident, more than 100,000 packages’ most recent
releases depended on a version of colors, and around half of them had
a dependency on a problematic version. The following graph shows the
dependency flow in the ecosystem over the 72 hours where the action
happened.
The number of packages dependent on different versions of colors.
About half the packages depending on colors remained unaffected
throughout the incident because they depended on earlier versions of
colors. But the other half of packages had some rapid and widespread
changes in the exact version of colors that would have been used
depending on the time at which their dependencies were resolved.
The first problematic version was 1.4.44-liberty-2. Due to version
naming conventions this isn’t considered a stable version and as a
result it wasn’t depended on by many packages.
A few hours later version 1.4.1 was released, and almost all packages
using the 1.4 minor version immediately began to depend on this
problematic version. Several hours later, 1.4.2 was released, and
again most packages affected by the incident immediately depended on
this new problematic version. After a few more hours npm stepped in
and removed all the bad versions of colors, at which point all
dependents moved back to safe versions.
The speed of this incident impacting the ecosystem was rapid. But so
too was the rapid response of maintainers. Between the initial release
of bad versions and their removal from npm, a period of less than 72
hours, nearly half of all affected packages were able to mitigate the
issue. A small number of packages were able to remove their dependency
on colors, about 4% of affected packages, seen as a drop in total
number of dependent packages. Many more packages, 40% of those
affected, were able to pin the version of colors being used to a safe
version. This can be seen in the gradual increase of packages
depending on an unaffected 1.4.x version.
Interestingly this rapid mitigation was the work of very few
people. Just a little over 1% of the affected packages actually made a
release during this time period. But their work resulted in 43% of the
total affected packages mitigating the issue. This is a result of the
same use of open dependency requirements that allowed the rapid spread
of the issue and enabled rapid mitigation.
Every dependency is a trust relationship
The colors and log4shell incidents were very similar in terms of
wide-reaching impact, but quite different in onset and response. In
the case of log4shell, a new vulnerability was discovered in old and
widely used versions, resulting in a need for dependents to move to a
new release of the package. In the case of colors, a new release
introduced breaking changes. This resulted in an initial automated
surge to the problematic version, followed by a concerted effort for
dependents to move to an older release of the package.
While the widespread use of open dependency constraints in npm led to
a rapid and widespread impact of colors, it was also helpful in its
mitigation. Conversely Maven’s approach of favoring stability resulted
in difficulty resolving log4shell, but also means Maven is much less
susceptible to a colors-type incident. Neither approach is obviously
superior, just different.
While there is no silver bullet solution, there are best practices
that consumers, maintainers, and packaging system developers can
observe to reduce risk. Always understand your dependencies and why
they were chosen, and always make sure your dependency requirements
are well maintained.
James Wetter and Nicky Ringland, Open Source Insights Team
More than 17,000 Java packages, amounting to over 4% of the Maven
Central repository (the most significant Java
package repository), have been impacted by the recently disclosed
log4j vulnerabilities
(1,
2), with
widespread fallout across the software industry.1 The
vulnerabilities allow an attacker to perform remote code execution by
exploiting the insecure JNDI lookups feature exposed by the logging
library log4j. This exploitable feature was enabled by default in many
versions of the library.
This vulnerability has captivated the information security ecosystem
since its disclosure on December 9th because of both its severity and
widespread impact. As a popular logging tool, log4j is used by tens of
thousands of software packages (known as artifacts in the Java
ecosystem) and projects across the software industry. User’s lack of
visibility into their dependencies and transitive dependencies has
made patching difficult; it has also made it difficult to determine
the full blast radius of this vulnerability. Using Open Source
Insights, a project to help understand open source
dependencies, we surveyed all versions of all artifacts in the Maven
Central Repository to determine the scope of
the issue in the open source ecosystem of JVM based languages, and to
track the ongoing efforts to mitigate the affected packages.
How widespread is the log4j vulnerability?
As of December 16, 2021, we found that over 17,000 of the available
Java artifacts from Maven Central depend on the affected log4j
code. This means that more than 4% of all packages on Maven Central
have at least one version that is impacted by this vulnerability.1
(These numbers do not encompass all Java packages, such as directly
distributed binaries, but Maven Central is a strong proxy for the
state of the ecosystem.)
As far as ecosystem impact goes, 4% is enormous. The average ecosystem
impact of advisories affecting Maven Central is 2%, with the median
less than 0.1%.
Maven ecosystem affected by the vulnerability
Direct dependencies account for around 3,500 of the affected
artifacts, meaning that any of its versions depend upon an affected
version of log4j-core as described in the CVEs. The majority of
affected artifacts come from indirect dependencies (that is, the
dependencies of one’s own dependencies), meaning log4j is not
explicitly defined as a dependency of the artifact, but gets pulled in
as a transitive dependency.
Direct dependencies vs. indirect dependencies
What is the current progress in fixing the open source JVM ecosystem?
We counted an artifact as fixed if the artifact had at least one
version affected and has released a greater stable version (according
to semantic versioning) that is unaffected. An
artifact affected by log4j is considered fixed if it has updated to
2.16.0 or removed its dependency on log4j altogether.
At the time of writing, nearly five thousand of the affected artifacts
have been fixed. This represents a rapid response and mammoth effort
both by the log4j maintainers and the wider community of open source
consumers. That leaves over 12,000 artifacts affected, many of which
are dependent on another artifact to patch (the transitive dependency)
and are likely blocked.
An example of affected artifact blocked by an intermediate dependency
Why is fixing the JVM ecosystem hard?
Most artifacts that depend on log4j do so indirectly. The deeper the
vulnerability is in a dependency chain, the more steps that may be
required for it to be fixed. The following diagram shows a histogram
of how deeply an affected log4j package (core or api) first appears in
consumers dependency graphs. For greater than 80% of the packages, the
vulnerability is more than one level deep, with a majority affected
five levels down (and some as many as nine levels down). These
packages may require fixes throughout all parts of the tree, starting
from the deepest dependencies first.
Depth of log4j dependencies
Another difficulty is caused by ecosystem-level choices in the
dependency resolution algorithm and requirement specification
conventions.
In the Java ecosystem, it’s common practice to specify
“soft”
version requirements — exact versions that are used by the resolution
algorithm if no other version of the same package appears earlier in
the dependency graph. Propagating a fix often requires explicit action
by the maintainers to update the dependency requirements to a patched
version.
This practice is in contrast to other ecosystems, such as npm, where
it’s common for developers to specify open ranges for dependency
requirements. Open ranges allow the resolution algorithm to select the
most recently released version that satisfies dependency requirements,
thereby pulling in new fixes. Consumers can get a patched version on
the next build after the patch is available, which propagates up the
dependencies quickly. (This approach is not without its drawbacks;
pulling in new fixes can also pull in new problems.)
How long will it take for this vulnerability to be fixed across the entire ecosystem?
It’s hard to say. We looked at all publicly disclosed critical
advisories affecting Maven packages to get a sense of how quickly
other vulnerabilities have been fully addressed. Less than half (48%)
of the artifacts affected by a vulnerability have been fixed, so we
might be in for a long wait, likely years.
But things are looking promising on the log4j front. After less than a
week, around 25% of affected artifacts have been fixed. This, more
than any other stat, speaks to the massive effort by open source
maintainers, information security teams and consumers across the
globe.
Where to focus next?
Thanks and congratulations are due to the open source maintainers and
consumers who have already upgraded their versions of log4j. As part
of our investigation, we pulled together a
list
of 500 affected packages with some of the highest transitive usage. If
you are a maintainer or user helping with the patching effort,
prioritizing these packages could maximize your impact and unblock
more of the community.
We encourage the open source community to continue to strengthen
security in these packages by enabling automated dependency updates
and adding security mitigations. Improvements such as these could
qualify for financial rewards from the Secure Open Source Rewards
program.
You can explore your package dependencies and their vulnerabilities by
using Open Source Insights.
When this blog post was initially published, count numbers
included all packages dependent on either log4j-core or log4j-api,
as both were listed as affected in the CVE. The numbers have been
updated to account for only packages dependent on log4j-core. ↩↩2
We’re pleased to announce deps.dev now has support
for Python packages hosted on the Python Package Index (PyPI). That
means we have over 300k—and counting—Python packages for your
perusal, from boto3 to
pandas.
Where does the data come from?
We use PyPI’s RSS Feeds to
stay abreast of new and updated packages, with an occasional full sync from the
Simple Repository API.
For each package version, we fetch metadata from the
JSON API and analyze it
to resolve its dependencies, determine the license, and so on.
Dependency resolution is complex in any language, and Python is no
exception. Sometimes you might see an error message about a particular version
of a package. The most common reason for this is packages that only provide a
source distribution
that specifies the dependencies in a setup.py—which is hard to run safely and
may not even be deterministic. This is not a problem with
wheels
as they do not require executing arbitrary Python code to understand the
dependencies. Of course there are any number of other things that can go wrong,
and Python has a long history of packaging formats, so if you find anything not
working as expected, don’t hesitate to
get in touch.
Where do the dependencies come from?
We periodically resolve the full dependencies of every package version we know
about. In pip terms, the graph we show for version 1.0.0 of package a consists
of the packages that would be installed by running pip install a==1.0.0 in a
clean environment with recent versions of setuptools and wheel available.
These graphs are dependent on the versions of both Python and pip, as well as
the operating system, CPU architecture, and so on. It’s not uncommon for
packages to publish different wheels for various different combinations of all
of these, and for each release to have its own metadata with potentially
distinct dependencies. Currently we perform resolution as if we were runnning
pip 21.1.3 with Python 3.9 on an x86_64
manylinux compatible platform, with more
combinations on the way. We think it’s an accurate reproduction but if you see
anything unexpected, please let us know!
What’s next
We’re excited to add PyPI to our set of supported language ecosystems, and
epecially keen to start digging into the data and do some comparative
analysis. From our first look, there are plenty of interesting things to
uncover, for instance:
4 of the 5 most depended on packages are all dependencies of the 6th most
depended on package: requests
more than half of all package versions on PyPI have zero dependencies,
compared to ≈15-25% across Go, npm, Cargo and Maven
this small package has one
of the lowest ratios of direct to indirect dependents we’ve seen across all
package ecosystems.
We’re also working on improving our license recognition and figuring out how to
show the differences enabling various
extras makes to the
dependency graphs.
So slither on in and start exploring! We’ll keep digging into the data and keep
you posted on what we discover!
Modern software is more than just some lines of code checked into a repository.
To build almost any program, one must also install packages from other
developers. These external dependencies are critical components of today’s
software environment, and tooling has been created to make it easy to install
dependencies and update them as required. As a result, the past few years have
witnessed a phenomenal growth in the open source ecosystem as well as a marked
increase in the average number of dependencies for a given package. Meanwhile,
many of these packages are being changed—fixed, expanded,
updated—regularly.
The rate of change is significant. Our analysis shows that roughly 15% of the
packages in npm see changes to their dependency sets each day, while a majority
of the change is in packages that are widely used.
This activity affects not just your own software, and not even just the
software you call upon, but the entire set of your software’s dependencies,
which may be much larger than those listed explicitly by your project. It is
common to see one package use a handful of other packages that in turn have a
hundred or more dependencies of their own. Many of the most commonly used
packages in open source have large dependency trees that will be pulled in by
the installation process.
Today’s software is therefore built upon a constantly-changing foundation, and
keeping track of that churn is challenging. Your package changes, your
dependencies change, their dependencies change, and so on. Even the most
diligent developers struggle to keep up beyond letting the tooling download
updates to all the dependencies from time to time. Tooling helps manage the
updates, but cannot guarantee what the right update is, or when the time is
right to apply it.
It’s easy to miss important problems deep in the dependencies, such as security
vulnerabilities, license conflicts, or other issues. The tools just do what
they are told, and if a nested dependency has an issue, it will be installed
regardless. Systems have been compromised or exploited by dependencies that
acquired malicious changes that were undetected, sometimes for long periods.
The Open Source Insights project aims to help. It collects
information about open source projects—source code, licenses, releases,
vulnerabilities, owners, and more—and gathers it into a single location,
making it accessible. These interfaces help developers and project owners see
the full dependency graph of their projects and can use it to track release
activity, vulnerabilities, and other information such as licenses that are used
by the components, regardless of how deeply they are nested inside the
dependencies.
In short, all the information about a package is connected to all the other
packages that depend upon it, and Insights shows the connections. For instance,
if your code depends on a package that has a security vulnerability, even if
that vulnerability is in a package 10 dependency hops away in a package that
you don’t even know about, the Insights page for your package will tell you
about it.
The Insights project also helps developers see the importance of their project
by showing the projects that depend on them—their dependents. Even a small
project is important if a large number of other projects depend on it, either
directly or through transitive dependencies.
This blog
To build deps.dev we dove deep into the fundamentals of
several different package management systems, collecting and organizing the
metadata of millions of packages, and implementing our own bug-for-bug
compatible semver parsers, constraint matchers, and
dependency resolvers.
Along the way, we’ve learnt about the wider problem space, and the varied
challenges that await the unsuspecting programmer. The tools are changing,
and inconsistent, and often poorly understood. Many package management systems
were not designed with today’s security concerns in mind. Semver constraints
are not formally specified, and are implemented arbitrarily by different
package managers. There is not widespread agreement on foundational questions
such as whether it is better to select the newest or oldest matching version,
or whether the ability to “pin” versions is a good or bad thing (and what that
even means). Also whether it is good or bad (or possible or impossible) to be
able to include multiple versions of the same package in a given program.
In future articles we will explore these issues in detail, comparing the
approaches of various communities, so as to contribute to the conversations
that push the open source ecosystem forward. We hope that we can converge, as
an industry, on some fundamental “good ideas” in the space of managing software
dependencies.